From NISQ to FTQC to FASQ

Table of Contents
Introduction
The dream of quantum computing is inching closer to reality, but between our current noisy prototypes and tomorrow’s transformative machines lies a daunting gulf. In the language of the field, we are transitioning from the NISQ era into the realm of FTQC, with an eye on the ultimate prize dubbed FASQ. These acronyms – Noisy Intermediate-Scale Quantum, Fault-Tolerant Quantum Computing, and Fault-Tolerant Application-Scale Quantum – chart the evolution of quantum computers from today’s limited devices to future error-corrected engines of discovery.
Decoding the Acronyms: NISQ, FTQC, and FASQ
NISQ – Noisy Intermediate-Scale Quantum
“NISQ” rhymes with “risk,” as its originator John Preskill likes to note. Preskill, a theoretical physicist at Caltech, coined the term in 2018 to describe the era we’re in now. “Intermediate-Scale” refers to quantum processors with tens or hundreds of qubits – enough that we can’t brute-force simulate them easily with classical supercomputers. They are noisy because these qubits are error-prone and not protected by full error correction. In essence, NISQ devices are impressive feats of engineering and have achieved quantum advantage in laboratory tests – performing tasks too complex for classical simulation. However, they remain research prototypes: their operations suffer from decoherence and gate errors, limiting their computational power.
So far, no practical commercial problem has been solved faster by a NISQ machine than by a classical computer. Preskill’s point in naming this era was to set realistic expectations: NISQ technology can do interesting experiments and explore quantum phenomena, but it’s uncertain if it can deliver useful quantum advantage without a leap in fidelity.
FTQC – Fault-Tolerant Quantum Computing
If NISQ is the rickety experimental aircraft, FTQC is the sturdy airliner we eventually want to build – a quantum computer that can fly through long calculations without crashing from errors. “Fault-tolerant quantum computing” isn’t attributed to a single coiner; rather, it emerged from the pioneering theoretical work of the 1990s. Scientists like Peter Shor, Andrew Steane, and others discovered quantum error-correcting codes (starting around 1995) and proved that if physical error rates can be pushed below a certain threshold, one can string together arbitrarily long quantum computations reliably. In 1997, Preskill himself wrote about the possibility of “reliable quantum computers” based on these principles.
The term FTQC simply denotes quantum computers with error correction, able to detect and fix their own mistakes on the fly. In an FTQC system, many physical qubits act together as one logical qubit that is far more stable. The goal is to have logical gate error rates much lower than physical error rates, so that large algorithms (with millions or billions of operations) can run to completion. Achieving FTQC is widely seen as the “road through” to economically relevant quantum computing. However, it comes at a steep price in complexity: as we’ll see, implementing error correction demands significant overhead in qubit count and engineering effort.
The concept of FTQC has been around for decades, but only now are we seeing early laboratory demonstrations that hint it’s becoming achievable in practice.
FASQ – Fault-Tolerant Application-Scale Quantum
This unwieldy phrase represents the endgame: a quantum computer that not only is fault-tolerant, but also large and versatile enough to run a wide variety of useful applications. The term FASQ was popularized in late 2024 by John Preskill (with credit to quantum scientist Andrew Landahl for suggesting the acronym). Preskill introduced FASQ to describe the distant goal beyond the NISQ era – machines that are fully error-corrected and big enough to tackle problems of practical interest. In his keynote at the Q2B 2024 conference, Preskill envisioned “FASQ machines, Fault-Tolerant Application-Scale Quantum computers that can run a wide variety of useful applications”.
In other words, FASQ implies quantum computers at a scale where they deliver broad quantum value – addressing real-world use cases in chemistry, materials science, finance, cryptography, and more, on a regular basis. If NISQ is the prototype and FTQC is the first working vehicle, FASQ is the mass-produced automobile. It’s the level at which quantum computing would become an everyday tool, not just a specialized experiment.
Notably, FASQ is a forward-looking term; no such machine exists today, and reaching that point is still a rather distant goal. By naming it, researchers convey optimism that fault-tolerant quantum computing will eventually reach application-scale impact, even if it takes years of hard work. (For trivia lovers: “FASQ” deliberately breaks from the NISQ naming pattern. Preskill chose to leave the “-ISQ” acronyms behind – though others have proposed terms like “Noisy Intermediate-Scale Real Quantum” etc., he jokes it might be better to speak in terms of quantum operations like megaquops and gigaquops instead!)
Crossing the Quantum Chasm: From NISQ to Early Fault Tolerance
Experts often talk about a “quantum chasm” or gap between the capabilities of NISQ devices and the requirements of useful quantum algorithms. Indeed, getting from NISQ to FTQC is not a sudden switch but a gradual, hard-fought transition.
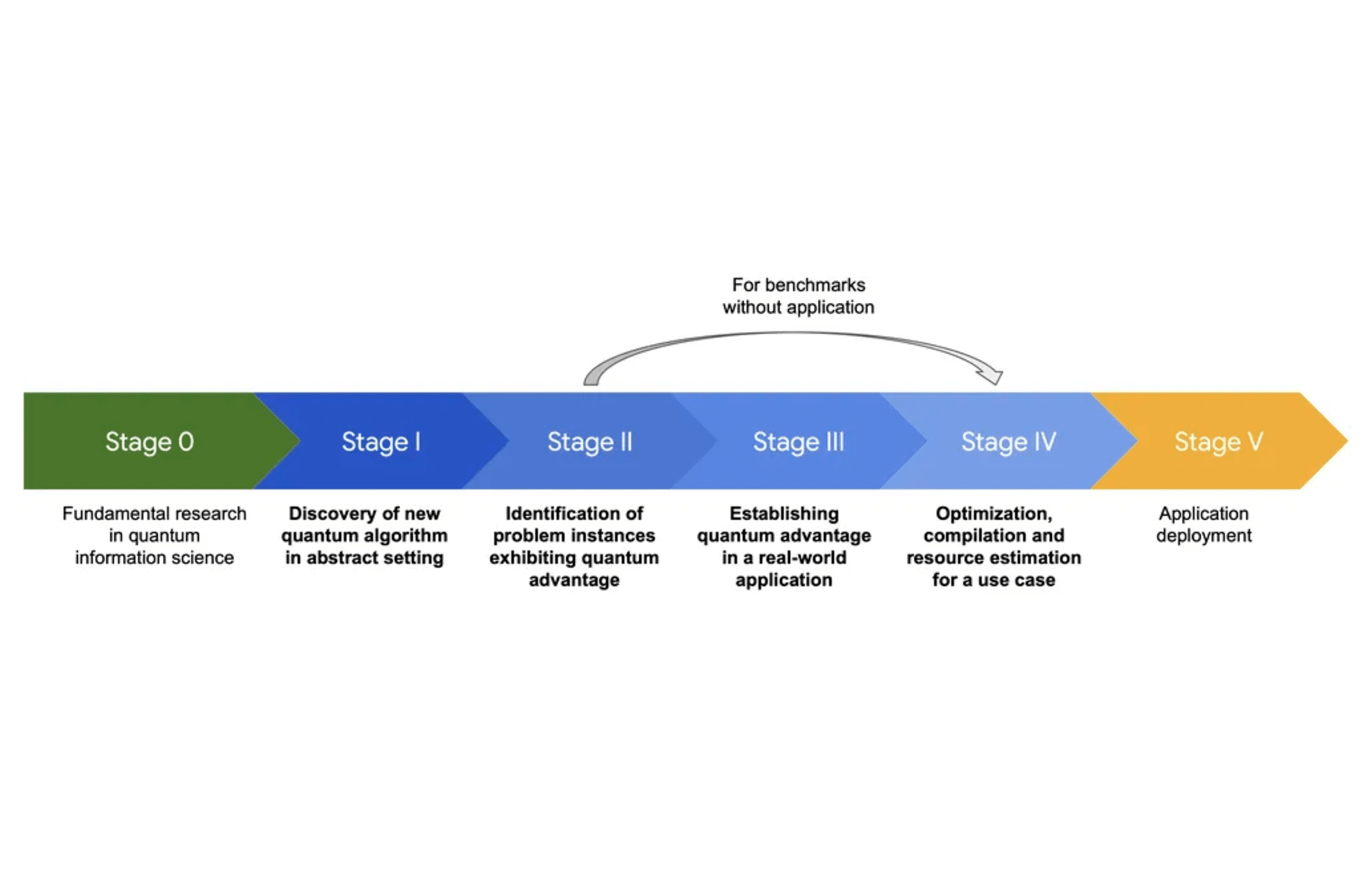
We can break this journey into two broad stages. In the first, we aim to go from NISQ’s error-prone calculations to actively error-corrected quantum operations. In practice, that means evolving from today’s error mitigation techniques to true error correction. In the second stage, we’ll go from a few error-corrected qubits to fully scalable fault-tolerant quantum computing, capable of solving hard problems with many logical qubits. Let’s look at stage one first.
Error mitigation vs. error correction
In the NISQ era, since we can’t yet eradicate noise, researchers have become crafty in squeezing the most out of noisy circuits. They use quantum error mitigation (QEM) methods – essentially clever post-processing tricks – to reduce the impact of errors on results. Popular examples include zero-noise extrapolation, where one deliberately increases noise in a circuit and extrapolates results back to an imaginary zero-noise limit, and probabilistic error cancellation, where one characterizes the noise and mathematically “unwinds” it from the outcomes.
These methods have indeed extended what NISQ machines can do. With error mitigation, quantum processors have run circuits with thousands of gates and still extracted a meaningful signal, as demonstrated in recent experiments by Google (103 qubits × 40 layers) and IBM (up to 5,000 gate circuits). However, there’s a catch: the cost of mitigation explodes exponentially as circuits get larger.
Essentially, to simulate a slightly less noisy circuit, one must run many noisy variants and average them – an effort that grows wildly with circuit depth. This means error mitigation alone won’t get us to quantum advantage for truly complex problems. As John Preskill bluntly put it, “error mitigation alone may not suffice to reach quantum value” because the overhead eventually becomes impractical. So, while QEM will “continue to be useful in the FASQ era” as a supplement, the real breakthrough comes from active error correction: building qubits that can detect and fix errors during computation, rather than just averaging them out afterward.
The first milestone on the road to FTQC, then, is to demonstrate a quantum memory or qubit that is genuinely protected from noise – outliving and outperforming the physical qubits it’s made from. In 2023, we saw promising evidence that this milestone is within reach. For example, Google’s Quantum AI team created a single logical qubit using a surface code (a popular error-correcting code) and maintained it through millions of error-correction cycles. By increasing the code size (distance 3 to 5 to 7), they observed that the logical error rate per cycle dropped roughly in half each time – a clear signature that the error correction was working as expected. This kind of result is crucial: it shows that if you throw more resources at the problem (bigger codes, more physical qubits), the qubit’s reliability improves. It’s a bit like testing a leaky boat: patch one hole and it still leaks, but patch more holes and eventually it stays afloat. The Google experiment indicated we’re patching holes faster than new ones appear, at least in a limited regime.
Likewise, other groups (such as researchers at ETH Zurich and Quantinuum) have prolonged the life of a qubit using error correction or demonstrated fault-tolerant gates on small logical qubits. All these are early signs that we’re crossing into the era of “early FTQC” – the very first, tentative steps out of the noisy regime.
In industry terms, some analysts predict we’ll see early fault-tolerant processors within the next five years, perhaps offering on the order of 100 logical qubits by the late 2020s. These wouldn’t be full-blown application-scale machines, but they could run certain algorithms with limited error correction.
It’s important to note that this transition won’t happen overnight with a single “wow” moment. Instead, NISQ and FTQC will overlap for some years. In fact, we may soon face an intriguing choice: would you prefer a quantum computer with, say, 10,000 physical qubits at 99.9% fidelity (but no error correction), or one with 1,000 physical qubits pieced into 100 logical qubits with 99.9999% fidelity? The former is a very advanced NISQ device; the latter is an early FTQC device. Each might be capable of certain tasks.
Many researchers are skeptical that even 10,000 noisy qubits can accomplish useful tasks, because not only does noise remain, but the algorithms for NISQ are heuristic and unproven. On the other hand, 100 error-corrected qubits could execute small versions of algorithms we know to be powerful (like quantum chemistry simulations or factoring small numbers). The likely scenario is that we’ll experiment with both approaches in parallel – pushing NISQ hardware to its limits while also nurturing the first protected qubits – until one clearly demonstrates an advantage.
During this period, picturing the challenge as bridging a chasm is apt: on one side, we have a larger and larger NISQ “army” of qubits marching, and on the other, a smaller but sturdier FTQC “bridge” being built. The race is to see which approach delivers a useful result first, and ultimately, the bridge (error correction) is expected to carry us further.
Scaling Up: From One Protected Qubit to Many (The Road to Full FTQC)
Let’s assume we clear the first hurdle and can build a handful of logical qubits that behave much better than physical ones. The next challenge is scale. To do anything broadly useful, we likely need hundreds or thousands of logical qubits running algorithms with perhaps billions of gate operations. This is where the requirements become staggering.
The state-of-the-art quantum error correction code (the surface code) illustrates the magnitude: if physical two-qubit gates have error rates around $$10^{-3}$$ , you would need on the order of ~1,000 physical qubits to create one very reliable logical qubit. That figure includes about 360 data qubits in the code, plus many auxiliary qubits for syndrome measurements (the process of detecting errors) and perhaps extra qubits for performing logical operations.
In concrete terms, a recent analysis showed that to run a sizable quantum algorithm (say, 1,000 logical qubits doing $$10^8$$ time-steps reliably), we might need almost a million physical qubits if using the surface code with $$10^{-3}$$ gate error rate. If physical qubit quality improves (e.g. $$10^{-4}$$ error rate), this overhead drops, but you’d still need on the order of hundreds of thousands of physical qubits for such a task. Today’s largest devices have on the order of a few hundred qubits. Clearly, there’s a long road ahead – one that will require not just incremental growth, but new breakthroughs in how we design and integrate quantum hardware.
Why do we need so many qubits? The fundamental reason is that error correction trades quantity for quality: you combat noise by redundancy. A logical qubit of error rate $$10^{-6}$$ or $$10^{-9}$$ (necessary for long algorithms) might be composed of hundreds of physical qubits each with error ~$$10^{-3}$$.
Moreover, error correction doesn’t just inflate qubit count; it also inflates the time it takes to run an algorithm. Many physical operations (error syndrome measurements, decoding steps, etc.) have to occur for each logical operation, and some logical gates require serial operations that can’t be fully parallelized due to how codes work. This means even once we have enough qubits, making the whole system run fast and efficiently is another engineering puzzle. In short, to scale up fault-tolerant quantum computing, we need orders-of-magnitude advances on multiple fronts: more qubits, better qubits, and smarter error correction schemes.
On the qubit count front, the challenge is as much architectural as it is about fabrication. How do you control one million qubits? How do you lay them out, supply signals, remove heat, and avoid cross-talk and errors coming from the environment? Researchers are exploring modular designs – for example, connecting many smaller quantum chips with optical or electrical links – so that we don’t have to have one monolithic chip with a million qubits. Classical computing faced a similar scaling issue in the 20th century (integrating millions, then billions of transistors), but quantum bits are more complex: they can’t just be wired up arbitrarily without introducing noise and delay. And speaking of delays, speed matters: if each logical operation takes too long, even a correct computation might be impractical in wall-clock time. Thus, engineers are keen to improve the clock speed of quantum operations, from faster qubit measurement and reset systems to cryogenic control electronics that can nimbly direct large arrays of qubits.
Meanwhile, on the qubit quality and error-correction front, there is intense work on new codes and protocols. The surface code has been a workhorse because it’s comparatively simple and tolerant of ~1% error rates, but it requires a 2D grid of qubits and a lot of overhead (as we saw). Newer quantum LDPC codes and other advanced codes promise far better encoding efficiency – some are “good” codes where the ratio of logical qubits to physical qubits is finite even as you scale up. For instance, certain LDPC codes or balanced product codes could encode, say, 100 logical qubits in a few hundred physical qubits (in theory) and still correct many errors. These could drastically reduce the overhead if we can implement them. The catch is they often require more complex connectivity or more complicated gate routines. Still, the theory community is pushing on this, and there have been prototypes of small LDPC codes on hardware. Even improvements like biased-noise qubits (where one type of error is suppressed and codes exploit that bias) or erasure conversion (where qubits turn certain errors into detectable “erasures”) can effectively lower the overhead by making errors easier to catch. The key idea is to shrink the gap between physical error rates and logical error rates with as little resource overhead as possible.
To appreciate the scaling challenge and progress, consider this metaphor: Today’s quantum computers are like early computers with only a few bytes of memory – we’re trying to perform complex computations with extremely limited, fragile storage. Error correction is akin to inventing ECC memory and redundancy; it’s as if we said, “to reliably store 1 byte, we need 1000 unreliable bits, but those 1000 bits together will behave as a perfect byte.” The task ahead is to cram enough of those “perfect bytes” into a machine and run them fast enough to do something useful. It took classical computing decades to move from kilobytes to gigabytes of reliable memory; quantum might be on a similar trajectory, albeit hopefully accelerated by the fact we already know how important error correction is.
Hardware Pathways: Superconductors, Ions, or Atoms?
How will we actually build these large-scale fault-tolerant machines? This is an open debate, and the stakes are high – it’s often compared to a “space race” of quantum technology. The three leading hardware modalities today are superconducting qubits, trapped-ion qubits, and neutral atom (often Rydberg atom) qubits. Each approach has its pros, cons, and passionate proponents. Let’s briefly survey them:
Superconducting Qubits
These are electronic circuits, typically tiny aluminum or niobium loops on a chip, that exhibit quantum behavior at millikelvin temperatures. Companies like IBM, Google, and Rigetti have bet on superconducting qubit processors.
Their advantages include extremely fast gate speeds – two-qubit gates can be as short as ~20-40 nanoseconds – and the ability to leverage modern nanofabrication methods (they’re built with lithography, somewhat like computer chips).
Superconducting qubits are arranged in a 2D grid with nearest-neighbor coupling in most designs. They typically use a configuration called the transmon qubit, which is an anharmonic oscillator that must be carefully designed and calibrated for quantum operations.
The state of the art has moved from 5-qubit chips a few years ago to devices with 127 qubits (IBM’s Eagle) and even 433 qubits (IBM’s Osprey) as of 2024, and over 100 qubits in Google’s latest “Sycamore” generation.
In terms of fidelity, superconducting platforms have achieved two-qubit gate error rates around 0.1% (99.9% fidelity) in the best cases. That’s among the best of any platform, though maintaining that across hundreds of qubits remains challenging.
The weaknesses? Since these qubits are basically artificial atoms, manufacturing variations can cause performance differences; they also require cryogenic refrigeration to about 10 millikelvin, which complicates scaling (imagine wiring up 1 million qubits and keeping them all ultra-cold).
Moreover, random bursts of radiation (like cosmic rays) can disrupt superconducting qubits, causing correlated errors – researchers have even considered whether future quantum data centers might need to be located underground or use mitigation techniques to avoid such events.
Superconducting qubits also have mostly local connectivity (each qubit talks mainly to its neighbors, though schemes exist to swap or shuttle quantum information across the chip). Scaling up may involve modularizing the architecture – for example, having multiple layers of chips or interconnecting modules with optical fiber – to avoid an impractical spaghetti of control wires entering a cryostat.
On the positive side, their fast operation means that even if error correction requires many cycles, those cycles can be executed quickly (millions per second is feasible, as Google’s experiment showed ~1 µs per cycle).
Trapped Ion Qubits
Imagine a line of individually charged atoms (like Ytterbium or Calcium) hovering above a chip, held in place by electromagnetic traps. Each ion encodes a qubit in two of its internal energy levels (for instance, two hyperfine levels that are extremely stable). Trapped-ion systems are pursued by IonQ, Quantinuum, and multiple labs.
Their big advantage is excellent coherence and uniformity: ions of the same species are identical by nature, and they can stay coherent for seconds or more. Single-qubit gates done with lasers on ions have fidelities 99.99% in many cases, and two-qubit gates have reached 99.7-99.9% fidelity in leading experiments.
Another advantage: ions in a trap are all-to-all connected in principle. By using shared vibrational modes of the ions or by physically transporting ions, any ion can interact with any other. This flexibility can simplify implementing complex error correcting codes which often need non-local interactions. Trapped ions, therefore, can use small numbers of physical qubits to do things that might require more in a strictly nearest-neighbor architecture.
The downside is speed and scaling. Two-qubit gates on ions are typically slow-ish: on the order of tens of microseconds (50 µs is common, sometimes a bit faster). To scale beyond ~50-100 ions in one trap, you either need to shuttle ions between traps (which introduces waiting times as ions move), or use multiple trap modules connected by photonic links. Companies are indeed pursuing such modular ion trap architectures, but it’s a complex challenge: one has to maintain stability while moving ions or entangling ions in different traps via photons.
Additionally, while ion traps don’t need dilution refrigerators, they do require ultra-high vacuum and a forest of laser beams or sophisticated optics to address individual ions. The engineering of laser delivery and stability becomes hairy as you add more ions or more traps.
In summary, trapped ions are like the high-precision luxury cars of quantum computing – incredibly well-behaved qubits (smooth ride, low error “rates”) but currently not built for speed or mass production at the scale of thousands. Researchers are actively working on faster ion gates (using pulsed lasers or tighter traps) and on integrating photonic coupling for scaling.
An interesting note: Because ion qubits are so reliable, some experts expect them to be among the first to demonstrate a logical qubit with better-than-physical performance, even if ultimately other platforms might scale to larger sizes faster.
Neutral Atom (Rydberg) Qubits
A newer kid on the block, this approach uses neutral atoms (often Rubidium or Cesium) trapped in arrays of optical tweezers – basically grids of tightly focused laser beams that hold single atoms in place. Companies like Pasqal and QuEra, and academic groups, have made great strides here.
The qubits are again atomic energy levels, but two-qubit gates are done by exciting atoms to highly energetic states called Rydberg states where they become like large electric dipoles and interact strongly if they’re nearby. By arranging which atoms sit next to which (the tweezers can dynamically move atoms in some setups), you get a reconfigurable interaction topology.
Gate speeds for Rydberg-mediated gates are on the order of a few hundred nanoseconds to a microsecond – faster than ions, though typically a bit slower than superconductors.
Neutral atom arrays have already achieved hundreds of qubits (e.g., a recent demo had 256 atoms in a 2D array), and they are attractive for their natural scalability: using more lasers and a bigger vacuum chamber, one could imagine scaling to thousands of atoms.
They also operate at room temperature (though the apparatus is bulky with lasers and vacuum systems).
The challenges? Currently, two-qubit gate fidelities are improving but still lag somewhat (on the order of 1% error or a bit below in some experiments), and keeping hundreds of atoms trapped reliably and reloading lost atoms is non-trivial.
There’s also a limit to how fast you can reconfigure or move atoms without introducing error.
Nonetheless, Rydberg atom systems have the interesting property of analog mode as well – they can simulate physics by analog interactions in addition to digital gates, though for FTQC we focus on digital operations.
Some forecasts (including Preskill’s) have suggested that if any platform might leap to a “megaquop” scale (millions of operations) in just a few years, neutral atoms could be a dark horse – mainly because they have already shown the ability to handle lots of qubits at once. It remains to be seen if they can achieve the needed stability and error rates to run error correction; if yes, one could envision a Rydberg-based processor with tens of thousands of atoms where error correction is done in a 3D space (2D arrays over time, perhaps).
Of course, these are not the only approaches.
Photon-based quantum computers (light-based qubits) aim to encode qubits in light particles, which don’t decohere the way matter qubits do. They face a different set of hurdles, like probabilistic gates and detection challenges, but companies like PsiQuantum are pursuing photonic FTQC with the bold claim of reaching a million-qubit machine by the late 2020s using silicon photonics.
Semiconductor spin qubits (like electrons in quantum dots or donor atoms in silicon) are another route – basically tiny qubit “transistors” that could leverage existing chip fabrication. They are fast and small, but still in early development with just a handful of coupled qubits shown so far.
And then there’s the long-shot of topological qubits (Majorana zero modes, for example), which promise built-in error resilience; Microsoft has been famous for investing in this approach, though as of 2025 a truly topological qubit is yet to be realized reliably.
The bottom line is, it’s too soon to declare a winner. Superconducting qubits have momentum and industry investment, trapped ions have the highest fidelities, neutral atoms offer huge numbers, photonics and spins promise ultimate scalability, and hybrid approaches might combine strengths (for example, ions or superconductors linked by photonic interconnects).
It’s very possible that the first generation of FTQC will involve hybrid systems – perhaps modules of superconducting qubits networked together, or ion traps with photonic links, etc. Each modality also has sub-debates internally (transmon vs alternative superconducting qubit designs, microwave vs optical ion control, Rydberg atoms vs atom-based quantum logic via collisions, etc.), which is beyond our scope here.
The key point is that hardware matters for the path from NISQ to FTQC. Some approaches might get to a small FTQC faster but struggle to scale beyond, while others might scale but have more to prove in fidelity. It’s an engineering multi-front war, and progress is being watched eagerly. As Preskill noted, “future quantum processors with broad utility may be based on different hardware modalities and/or architectural principles than those now being avidly pursued” – a diplomatic way of saying we should keep our options open because the winning design might surprise us.
From Tricks to Truth: Algorithms on the Road to Quantum Advantage
Hardware is only half the story. The other half is algorithms and applications – in essence, what will these quantum computers do that’s so useful?
In the NISQ period, a lot of algorithms research has focused on near-term heuristics. These are methods like the Variational Quantum Eigensolver (VQE) or Quantum Approximate Optimization Algorithm (QAOA), which are designed to work within the tight constraints of NISQ devices (few qubits, shallow circuits) and involve a hybrid of quantum operations and classical optimization. They’ve produced some exciting scientific results, like small-scale chemistry simulations, but so far they haven’t delivered a knock-out blow where a NISQ device clearly beats the best classical methods for a practical problem. Part of the issue is that classical algorithms and hardware keep improving too – by the time a quantum chip does something noteworthy, classical computers find a clever way to simulate it or solve a similar problem. This leapfrog has been evident in areas like quantum simulation of materials: quantum computers do something novel, then classical algorithms catch up using new tricks, and so on. It raises the bar for what constitutes a true quantum advantage.
When we talk about moving to FTQC and FASQ, we’re implicitly assuming that error-corrected quantum computers will unlock algorithms that simply couldn’t run at all on NISQ devices (because they’re too deep or too large) and that those algorithms will have proven quantum advantages.
For instance, Shor’s algorithm for breaking RSA encryption requires thousands of logical qubits and billions of operations – totally out of reach for NISQ, but a clear exponential speedup in principle.
Quantum simulations for chemistry that might provide industrial value (like accurately computing reaction rates or materials properties) appear to need at least hundreds of logical qubits and very long circuits, again well beyond NISQ.
The fraught road to quantum advantage involves not just improving hardware but also closing algorithmic gaps. In practical terms, a verifiable algorithm is one where we have a solid argument (based on complexity theory or provable mathematics) that it will outperform any classical approach at a certain scale. With heuristic NISQ algorithms like QAOA or variational quantum machine learning, we lack such assurances – they might work well, or a classical heuristic might do just as well. In contrast, many algorithms designed for fault-tolerant machines (like certain quantum chemistry algorithms using phase estimation, or optimization algorithms leveraging Grover’s search as a subroutine) come with clearer performance guarantees if the machine is big and clean enough.
That’s why some experts are impatient for the FTQC era – they expect that only then can we run algorithms that really prove the worth of quantum computing. Quantum simulation of materials and chemistry is widely believed to be one of the first killer applications of FASQ machines, because quantum systems naturally simulate other quantum systems and classical methods struggle with that scale. We might need, hypothetically, on the order of 100 logical qubits and billions of operations to do something like crack a hard protein folding or chemistry problem – challenging but conceivable within a FASQ machine’s scope in the future.
Another likely domain is optimization or machine learning tasks where quantum computers could offer more than a quadratic speedup. While NISQ algorithms in optimization usually give at best polynomial (often quadratic) speedups, there are more theoretical algorithms (for fully error-corrected machines) that promise super-polynomial speedups in specific cases. One example is certain algebraic problems or fault-tolerant implementations of quantum sampling algorithms that tie into machine learning. If those become practical, a quantum computer might tackle a complex optimization in hours that classical computers couldn’t solve in years – that’s the kind of quantum advantage everyone’s chasing.
It’s also worth noting that the algorithmic landscape is evolving. Researchers are now actively designing algorithms for the “intermediate scale but error-corrected” era – sometimes called the ISQ era (Intermediate-Scale Quantum, a term coined by Xanadu’s Juan Miguel Arrazola). ISQ or “early FTQC” algorithms acknowledge that in the first generation of FTQC, we still won’t have millions of qubits; we might have, say, 50 or 100 logical qubits to work with, so we can’t just waste them. These algorithmic strategies involve tricks like reducing the number of expensive quantum operations (like magic state injections or non-Clifford gates), trading off circuit depth for qubit count, and so on. In other words, rather than assuming a perfect, huge quantum computer, they assume a small fault-tolerant one and optimize for its limitations. This is analogous to how early programmers of classical computers had to optimize code for very limited memory and CPU speed – they came up with clever methods to do more with less. As quantum developers, we’re relearning that skill set: for example, how to compile algorithms to surface-code circuits efficiently, or how to hybridize classical computing with quantum in new ways to offset quantum resource bottlenecks. The net effect is that by the time FASQ machines arrive, we should have a suite of algorithms ready to truly exploit them, as opposed to the situation now where we often can’t fully test our algorithms due to hardware limits.
Finally, let’s touch on one more “gap”: the move from exploratory demos to credible quantum advantage in simulation. Quantum simulation is a special case of algorithms – even today, NISQ devices have been used to simulate condensed matter physics or chemistry in regimes hard to study otherwise. However, those simulations are often exploratory: they’re interesting to scientists, but it’s hard to verify if they’re doing something a classical computer truly can’t, or if they’re giving new physical insight with rigor. To have a credible advantage, a quantum simulation would need to produce results that we either can’t replicate classically or that push into a new scientific territory (like modeling a quantum system of a size/complexity never done before) and have enough accuracy to trust. Achieving that likely requires some level of error correction so the simulator can run long enough and large enough without noise spoiling the result. It’s a stepping stone to FASQ: think of FASQ as broad usefulness, whereas a credible quantum advantage in simulation might be a narrower achievement (say, solving one specific hard physics problem) that proves the concept. We’re probably a few years away from even that kind of advantage, but it could come sooner than a general-purpose FASQ computer. When it does, it will be a strong validation that the long slog through improving qubits and algorithms was worth it.
In summary, the evolution of algorithms from NISQ to FASQ involves moving away from quick-and-dirty tricks toward robust, scalable approaches that dovetail with error-corrected hardware. It’s a shift from “What can we do with a few noisy qubits?” to “How do we best use a few dozen perfect qubits to solve something hard?” All the while keeping an eye on the endgame: algorithms that might run on thousands of qubits to do things we once thought impossible.
Toward the FASQ Era: A Look Ahead
We can draw an analogy between the state of quantum computing and the early days of human flight. The NISQ era has been our Kitty Hawk moment – we have seen quantum “planes” leave the ground, surprising the world with feats like quantum supremacy flights that classical machines couldn’t follow. But those flights were short and wobbly, and carried no passengers. The next phase, achieving fault tolerance, is like designing the first airplanes that can fly across the Atlantic reliably. It’s an enormous engineering challenge, requiring stronger materials (better qubits), new navigation systems (error correction codes and decoders), and bigger engines (scaling up qubit counts). And FASQ – the fully realized vision – is the equivalent of a global network of passenger jets or perhaps the Space Shuttle: quantum computers so capable and dependable that they become indispensable tools for industry and science, routinely accomplishing tasks that were previously unthinkable.
How long will it take to get there? Optimists point to the rapid pace of recent progress: for instance, the fact that we have seen >99.9% fidelity gates and that companies have detailed roadmaps aiming for thousands of qubits by the end of this decade. They argue that with enough investment and clever innovation (and perhaps some error-corrected qubits appearing sooner than expected), we could see prototypes of useful quantum processors in the late 2020s. Indeed, as noted, a few dozen logical qubits might start tackling specialized problems before 2030. Pessimists (or realists, as they’d say) remind us that each additional nine of fidelity is harder than the last, and scaling from 100 qubits to 1,000,000 is a monumental jump that could uncover new roadblocks. They suggest FASQ might not bloom until the 2030s or beyond, after a long period of refinement. History gives some counsel here: building the first fault-tolerant classical computers (with transistors and ECC memory) took decades of R&D from the point of first transistor. Quantum tech might accelerate thanks to better tools and global effort, but it still might be a marathon, not a sprint.
One thing is clear: the journey will require a holistic effort, from materials science to software engineering. Progress will require innovation at every element: hardware, control, error correction, and algorithms hand-in-hand. There’s a virtuous cycle to exploit: early fault-tolerant processors will guide application development, and the vision of important applications will guide technological progress. In other words, as soon as we have even a primitive FTQC, researchers will test new algorithms on it, discover what works well and what the bottlenecks are, and that feedback will inform the next hardware design. This tight interplay between theory and experiment has been a hallmark of quantum computing so far, and will only intensify. It’s akin to the evolution of classical computers – where improvements in hardware (say, a new GPU) enabled new applications (like deep learning), which then drove the creation of even better hardware (TPUs, etc.).
Another forward-looking insight is that we may witness hybrid approaches yield the first practical benefits. For example, error-corrected qubits might be used in tandem with a reservoir of noisy qubits. A speculative scenario: imagine a machine with 20 logical qubits to do the “important” parts of an algorithm error-free, assisted by 1000 cheap physical qubits that handle less critical tasks with mitigation. Such hybrids could act as a bridge between the eras – leveraging the strengths of NISQ and FTQC together. Already, ideas like “quantum circuit knitting” try to partition problems between smaller quantum pieces and classical computation. As we gain the ability to correct errors on some qubits, we’ll get creative in how to allocate our quantum resources for maximum impact.
In conclusion, the path from NISQ to FTQC and onward to FASQ is one of the most exciting technological journeys of our time. It’s a path filled with hard engineering problems, deep theoretical questions, and a fair share of skepticism to overcome. But each year, that path becomes a little clearer.
Quantum Upside & Quantum Risk - Handled
My company - Applied Quantum - helps governments, enterprises, and investors prepare for both the upside and the risk of quantum technologies. We deliver concise board and investor briefings; demystify quantum computing, sensing, and communications; craft national and corporate strategies to capture advantage; and turn plans into delivery. We help you mitigate the quantum risk by executing crypto‑inventory, crypto‑agility implementation, PQC migration, and broader defenses against the quantum threat. We run vendor due diligence, proof‑of‑value pilots, standards and policy alignment, workforce training, and procurement support, then oversee implementation across your organization. Contact me if you want help.
Related Content