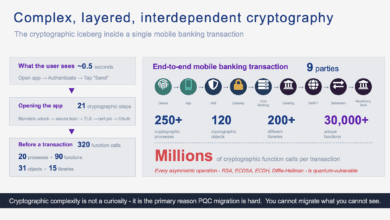
120,000 Tasks: Why Post‑Quantum (PQC) Migration Is Enormous

Table of Contents
Introduction: The Number That No One Believes
When I tell fellow CISOs, board members, or even seasoned program managers that the integrated program plan for a comprehensive quantum security / post-quantum cryptography (PQC) migration I recently worked on contained over 120,000 discrete tasks, the reaction is almost always the same.
First, there is a polite silence. Then, the inevitable furrowing of the brow. Finally, the question: “Surely, you mean you counted every single vulnerability as a task?”
They assume the number is an artifact of bad project planning or bad accounting – a “padding” of the stats where every server patch or every re-keyed certificate was listed as a separate line item to make the project look impressive. They assume that if we just grouped things logically, the number would collapse to a manageable 500 or 1,000 lines on a Gantt chart.
I assure you: that number is real. It is not inflated. In fact, for a Global 2000 enterprise with a heavy operational technology (OT) footprint, 120,000 tasks might be conservative.
I have served as a project manager on nation-critical overhauls: from the redevelopment of the UK’s centralized payments infrastructure, where downtime threatens the national GDP, to the implementation of Australia’s national electronic health records, a system impacting every citizen and practitioner in the country. I have stepped in to turn around failing $500M IT transformations. Yet, even with that background, I can say with certainty: the scale and complexity of making a global enterprise quantum-ready is a challenge in a category of its own.
A brief reality check: I am not suggesting that every organization should, or even can, launch a 120,000-task program on day one. In the real world of budget cycles and competing priorities, most will need to deconstruct this into manageable projects and multiple funding rounds. That is a valid, often necessary, approach. But even if your Year 1 roadmap only contains 500 tasks, you must understand the full 120,000-task horizon to properly prioritize, manage interdependencies, and avoid building on a foundation that won’t support the weight of the years to come.
But let me be clear about something: 120,000 tasks is just a number I used to illustrate the scale. It is not, on its own, the key message. The key message is complexity. This is a program assembled from dozens, or hundreds, of interlocking projects, executed by a large number of teams across organizational boundaries, with an enormous web of technical, organizational, and human interdependencies. Tasks can be counted; interdependencies are what make a program succeed or fail. It is the density of those dependencies – between vendors and internal teams, between infrastructure foundations and application waves, between regulatory timelines and engineering capacity, between legacy OT constraints and modern security requirements – that makes this qualitatively different from anything most organizations have attempted.
I have been warning about this scale for years. Through my work advising global telecommunications giants, financial institutions, and critical infrastructure operators; through my teaching (see e.g. SANS SEC529: Quantum Security Readiness for Executives) and in the articles I’ve published here on PostQuantum.com, I have tried to articulate a singular, uncomfortable truth: PQC migration is the largest, most complex digital infrastructure overhaul in history. And illustrate it on a telecom project. Such a project is larger than the Y2K remediation. It is more pervasive than any cloud migration. It is more technically intricate than the shift to Zero Trust. It makes your SAP S/4HANA migration look like a weekend project. And the math that gets you to 120,000 tasks is not pessimistic. It is arithmetic.
The “120,000 tasks” figure is not a measure of inefficiency. It reflects what happens when you stop treating cryptography as a background utility – like electricity, assumed to be always on and always safe – and start treating it as the structural steel of your digital existence. When that steel begins to fracture under the weight of the quantum threat, replacing it while the building is still occupied requires a level of orchestration that defies standard IT project management.
In this article, I will try again to illustrate the level of complexity based on such a 120,000-task plan. If you are a CISO or a direct report to one, this is intended to recalibrate your mental model for what lies ahead – and to give you the vocabulary to explain it to your board.
What a Task Means in an Integrated Master Schedule (IMS)
Let’s first clarify what I mean by a “task.” A six-figure task count becomes less mysterious once you understand what high-maturity programs mean by an “IMS task.” A defensible IMS is not a simple checklist. It is a dependency network capturing all authorized work, including external interfaces, government-furnished inputs, and relationship dependencies.
In U.S. Department of Energy (DOE) scheduling guidance, an IMS “shall include, at a minimum, discrete tasks/activities… and relationships necessary for successful contract completion,” with the schedule acting as the integrated network of the effort. The U.S. Government Accountability Office’s (GAO) schedule best practices similarly emphasize that a credible schedule reflects all activities tied to program scope and sequencing.
Now, translate that discipline into PQC migration. If you put “Upgrade TLS to PQC” as a single task, you are effectively admitting one of two things:
- You do not yet know the actual work, owners, or dependencies – meaning the schedule is not executable.
- You are consciously hiding risk – meaning the schedule is not governable.
Mature programs break work down because the dependencies are real and because leaders need to answer critical questions: What can start now? What is blocked by vendors? What must finish before a high-risk system can move? Where do we need outage windows? What evidence proves migration happened? CISA, NIST, NSA Official quantum-readiness guidance explicitly pushes programs in that direction by calling for inventories, risk analysis, and vendor engagement as the enabling substrate of migration.
This is why “120,000 tasks” is not breathtaking on its own. The meaningful question is what the program is trying to control:
- A global estate comprising IT, OT, and IoT.
- A multi-vendor supply chain.
- Long-lived confidentiality and integrity risks – HNDL (Harvest-Now, Decrypt-Later) and its signature-side twin, TNFL (Trust-Now, Forge-Later).
- A transition that must run in parallel with normal refresh cycles and major architecture programs like Zero Trust and network or identity modernization.
Governments are not asking nicely anymore
Before we talk about tasks, we need to talk about clocks. Not quantum clocks. Regulatory clocks. Because while organizations debate whether Q-Day arrives in 2030 or 2035, regulators around the world have stopped waiting and started mandating.
In August 2024, NIST finalized three post-quantum cryptography standards – FIPS 203 (ML-KEM), FIPS 204 (ML-DSA), and FIPS 205 (SLH-DSA) – ending a decade of algorithm competition. Within months, a global regulatory cascade began.
- NIST’s own IR 8547 transition guidance established a timeline that many regulators are now echoing: certain quantum-vulnerable mechanisms are slated for deprecation after 2030 and broad disallowance after 2035 (with security-strength nuances depending on the algorithm family and use case).
- The UK’s National Cyber Security Centre published a three-phase migration roadmap in March 2025: complete discovery by 2028, migrate high-priority systems by 2031, finish everything by 2035.
- Australia’s Signals Directorate went further, setting end of 2030 as the deadline for completing the full PQC transition – five years ahead of NIST’s outer bound.
- India mandated quantum-safe implementation for critical information infrastructure by December 31, 2029, with mandatory Cryptographic Bill of Materials submissions from financial year 2027-28.
- The European Union released its coordinated PQC implementation roadmap in June 2025, requiring member states to begin transitioning by end of 2026, secure all high-risk systems by end of 2030, and achieve full migration by 2035.
- Meanwhile, in the United States, Executive Order 14306 (June 2025) directed CISA to publish – and regularly update – a list of product categories where PQC-capable alternatives are widely available, and set federal expectations around modern protocol baselines (including TLS 1.3). CISA’s initial publication arrived in January 2026 as a procurement signal to accelerate vendor readiness across major commercial product categories.
- The NSA’s CNSA 2.0 timelines remain aggressive for national security systems and underscore why vendor and product readiness becomes a gating constraint: different technology categories have different “support/prefer/exclusive” target years, and “custom/legacy” categories tend to become waiver/replacement problems rather than “just upgrade it.”
- The Bank for International Settlements (BIS) published its quantum-readiness roadmap for the financial system in July 2025, warning that critical financial systems must be quantum-safe by the early 2030s and that uncoordinated actors could become “weak links” threatening the entire system.
This is not a single mandate from a single government. It is a synchronized global regulatory convergence with interlocking deadlines, compliance requirements, and enforcement mechanisms. And every one of these timelines assumes you have already started.
For multinationals, the hardest part is the deadline divergence. A serious program therefore runs a ‘regulatory horizon scanning’ loop: map external expectations by geography and sector, translate them into internal domain targets (PKI, VPN, code signing, identity, OT), and refresh that mapping as standards and procurement requirements evolve. In schedule terms, it becomes recurring governance work and recurring audit evidence work over a 7–10 year horizon.
The gap between mandate and reality is staggering. The IBM Quantum-Safe Readiness Index for 2025, surveying 750 executives, found the average organization scores just 25 out of 100 on quantum-safe readiness. Even the top 10 percent – IBM’s “Quantum-Safe Champions” – scored only 35 to 50. And 62 percent of respondents told IBM they believe their vendors will “handle” the quantum-safe transition for them – a belief that will age poorly. Multiple other industry surveys echo the same pattern: limited formal roadmaps, incomplete cryptographic inventories, and an over-reliance on suppliers to “make it go away.”
This is not Y2K 2.0 – it is an order of magnitude harder
The Y2K comparison is the first one everyone reaches for, and the first one that falls apart under scrutiny. Y2K was a contained problem with a fixed, universally understood deadline. The fix was conceptually simple: find two-digit year fields, expand them to four digits, test. Global remediation was painful, expensive, and ultimately successful because the problem was well-bounded.
PQC migration is different in almost every dimension. There is no single “flag day.” The threat timeline is uncertain – and it is also highly sensitive to algorithmic improvements, not just hardware roadmaps. Craig Gidney’s work (Google) is an example of why estimates can shift: successive analyses have substantially reduced the resource estimates for breaking RSA-2048 compared with 2019-era baselines, reminding us that “Q-Day” can arrive sooner than expected even if hardware progress is uneven. And in February 2026 researchers from Iceberg Quantum suggested an approach that could reduce estimates further (with large caveats and “ifs” that should not be treated as planning guarantees). Multiple quantum computing companies have roadmaps targeting roughly one million qubits by 2030, suggesting Q-Day could plausibly arrive within five years in optimistic scenarios.
But unlike Y2K, the threat is already active: adversaries are conducting harvest-now, decrypt-later attacks today, capturing encrypted data that will become readable once quantum capability arrives. For data requiring long-term confidentiality – classified information, healthcare records, intellectual property, financial instruments – the window for protection is already closing.
The Citi Institute’s January 2026 report framed the stakes in systemic terms: quantum-enabled compromise of critical financial infrastructure is not “just another breach.” Citi described the quantum threat as requiring “the largest upgrade of cryptography in human history, far bigger than the Y2K transition.“
Historical cryptographic transitions confirm the time scale. The migration from SHA-1 to SHA-2 – a relatively straightforward algorithm swap – took approximately seven years from NIST’s 2011 deprecation to browsers fully rejecting SHA-1 certificates in 2017, and required coordinated enforcement by browser vendors and certificate authorities. The transition from 1024-bit to 2048-bit RSA keys took roughly a decade. PQC migration is substantively more complex than either of these. The Enterprise PQC Migration Study published in MDPI’s Computers journal in December 2025 estimated timelines of 5 to 7 years for small enterprises, 8 to 12 years for medium enterprises, and 12 to 15+ years for large enterprises under baseline assumptions. One major telecom operator I have advised on quantum readiness for nearly a decade is still nowhere close to the finish line.
Where Y2K required finding and fixing date fields, PQC migration requires discovering, inventorying, risk-assessing, redesigning, testing, and replacing every instance of quantum-vulnerable cryptography across every system, device, application, protocol, and third-party integration in an enterprise – while maintaining 24/7 operations, coordinating with hundreds of vendors, retraining staff, rebuilding PKI infrastructure, managing regulatory compliance across multiple jurisdictions, and adapting to standards that are still evolving. The SAP S/4HANA migration – itself considered one of the most complex enterprise technology transitions – routinely exceeds timelines and budgets. PQC migration is an order of magnitude more complex, touching every system rather than one business platform.
Cryptography runs deeper than anyone thinks
The fundamental reason the task count reaches 120,000 is that cryptography is woven into every layer of every system, often invisibly, and each instance creates a distinct work package when it needs to change.
Consider what happens during a single modern 5G phone call. The subscriber’s USIM holds a long-term secret key shared with the home network’s authentication server. The 5G-AKA protocol runs a symmetric-key authentication handshake using MILENAGE or TUAK algorithms, generating cipher keys, integrity keys, and an anonymity key. The device encrypts its permanent identifier (SUPI) into a concealed identifier (SUCI) using ECIES with an ephemeral elliptic curve key pair, deriving a shared secret and encrypting with AES-128 in CTR mode plus an HMAC-SHA-256 integrity tag. A key derivation hierarchy produces separate keys for the Access Management Function and the radio interface, each using HMAC-SHA-256. The radio link encrypts user data with SNOW 3G, AES-128, or ZUC stream ciphers and protects signaling integrity with AES-CMAC. Backhaul connections between base stations and core network run through IPsec tunnels using IKEv2 with Diffie-Hellman key exchange and X.509 certificates. The 5G core’s service-based architecture protects inter-function communication with TLS using ECDHE key exchange, certificate-based authentication, and AES-GCM bulk encryption, plus OAuth2 tokens for API authorization. Roaming traffic passes through Security Edge Protection Proxies using mutual TLS plus JSON Web Encryption and JSON Web Signatures. Voice calls add IMS authentication, SIP signaling over TLS, and SRTP media encryption negotiated through DTLS handshakes.
That is hundreds of distinct cryptographic operations, spanning symmetric and asymmetric algorithms, across multiple protocol layers, involving separate certificate hierarchies, key management systems, and hardware security modules – in a single phone call. Every one of the asymmetric operations is quantum-vulnerable. Many of the supporting systems – certificate authorities, key derivation functions, HSMs – will need to change.
Now multiply by every service a telecom operator provides. And recognize that the phone call example does not even touch billing systems (HTTPS, SFTP, digital signatures on charging records), network management (SSH, NTP authentication, SNMP), software update pipelines (code signing, secure boot, firmware integrity), or the entire operational technology layer running power systems, HVAC, physical security, and environmental monitoring.

The interbank payment system tells a parallel story. I have managed massive payments redevelopment programs and secured SWIFT systems for global banks, and the cryptographic depth still surprised me when I mapped it comprehensively. Customer-to-bank channels use TLS with ECDHE and AES-GCM, plus MFA with HMAC-based TOTP, plus mobile app encryption with certificate pinning and OAuth tokens. Inside the bank, data-in-transit uses mutual TLS between microservices, IPsec between network segments, and SSL/TLS on messaging middleware. Data-at-rest uses AES-256 database encryption, column-level encryption, tokenization of payment card numbers. Audit logs are cryptographically signed with SHA-256 hash chains. SWIFT operations run on PKI certificates stored in FIPS 140-2 Level 2+ HSMs, with message authentication via digital signatures replacing legacy bilateral 128-bit 3DES MACs. RTGS settlement systems layer VPN encryption, application-level TLS, hardware token authentication, and cryptographically signed payment messages.

Pick any larger use case from your industry and the complexity will be similar to these two examples.
And beneath all of this lies what I call the “hidden crypto” layers – the cryptographic operations that don’t appear in any architecture diagram. Device trust anchors and secure boot. OS-level disk and memory encryption. Container image signing and service mesh mutual TLS. MACsec on network links and DNSSEC on name resolution. SAML, OIDC, FIDO2, and client certificates in the identity plane. EMV chip cryptography and PIN encryption in payments adjacencies. BMC secured channels and code-signing in operational infrastructure. Third-party API encryption across fintech integrations and correspondent banking gateways.
Two discovery multipliers are routinely underestimated. First, unmanaged endpoints and BYOD (and “shadow IT” SaaS) can introduce cryptographic dependencies that never pass through traditional architecture governance. Second, ephemeral cloud (autoscaling, containers, serverless) can generate machine identities and certificates at a rate that makes point-in-time inventories obsolete. These are not edge cases – they are why modern discovery needs automation, and why inventories must be treated as “living systems.”
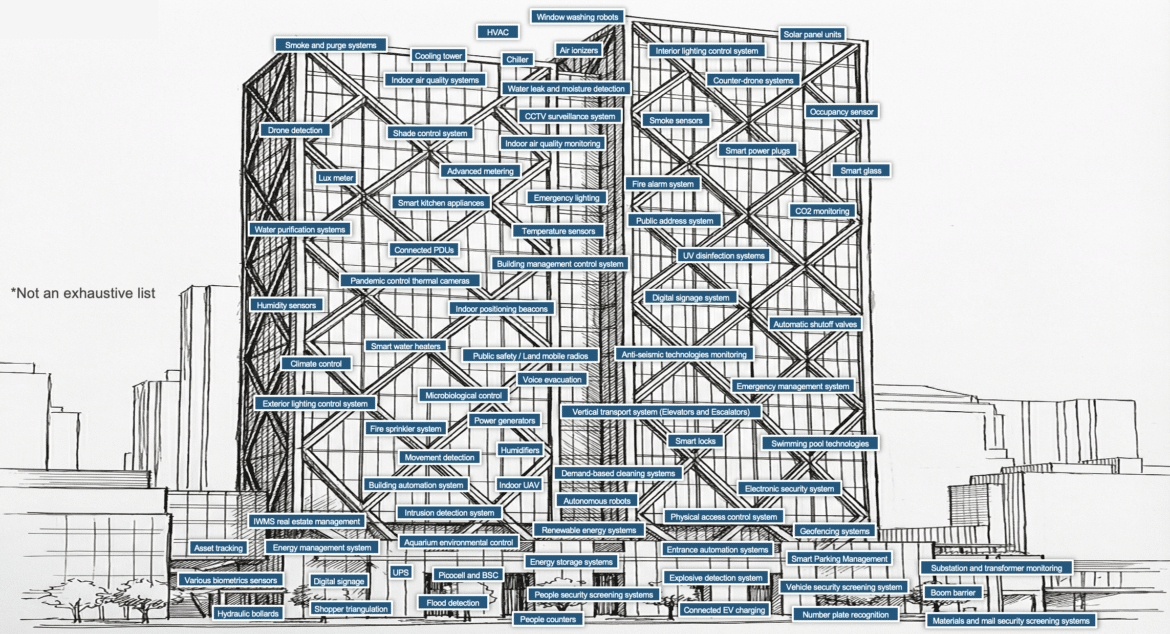
Or, in another example of “hidden crypto”, in one recent assessment, I helped a client discover over 160 distinct categories of connected “smart” devices in a single office building – not 160 devices, but 160 types, each with its own hardware, firmware, and cryptographic dependencies, installed by facilities management, corporate security, and engineering teams operating outside IT governance. The IT was not aware of them. If these devices connect to your network, and most do, these are potential vulnerabilities that would also need to be assessed and mitigated.
The multiplication that reaches 120,000
Understanding the depth of cryptographic integration is necessary but not sufficient to explain 120,000 tasks. You also need to understand how the dimensions of the program multiply – and how high-maturity schedules count work.
A (simplified) PQC migration program would have:
- four major phases:
- Discovery
- Assessment and Planning
- Implementation, and
- Operations.
- It would normally have at least ten parallel workstreams:
- cryptographic inventory maintenance,
- cryptographic strategy and approved mitigation patterns and PQC algorithm selection and validation,
- crypto-agile architecture and development,
- infrastructure and network upgrades,
- application and software remediation,
- PKI and key management,
- vendor and supply chain management,
- standards and regulatory alignment,
- lawful interception and legal obligations (for regulated industries),
- and training and change management
And it operates across an enterprise with hundreds to thousands of applications, tens of thousands of network elements, hundreds of thousands of certificates, and potentially millions of connected devices.
Here is the key point that fixes most task-count confusion: in a serious IMS, you do not create one task per certificate, one task per server, or one task per crypto finding. You create tasks for repeatable work packages (e.g., “migrate this service tier in this region using this approved pattern”) plus the recurring execution system that makes those packages safe (governance cadence, vendor enforcement, testing/assurance, metrics/evidence, workforce absorption, and operational controls). That is how six-figure schedules happen without “padding.”
The other 90,000 tasks: the enterprise enablement work that actually drives the count
Most skepticism about six‑figure schedules comes from a hidden assumption: that the plan is mostly a giant list of cryptographic “fixes.” In reality, large task counts are usually driven more by the work that enables cryptographic change than by cryptographic change itself.
That framing is not just my opinion – it is how mature guidance describes the transition. NIST’s crypto‑agility guidance explicitly treats agility as a strategic and tactical capability integrated into enterprise risk management and governance – not a one‑time engineering sprint. It spans how cryptography is designed, implemented, acquired, deployed, monitored, and continuously adapted as standards and supply chains evolve. Mature crypto‑agility also implies recurring work: organizational awareness and training, integrated and automated discovery/remediation tooling, and continuous testing of agility practices so the organization can actually activate them under pressure.
Policy guidance makes the same point in operational language. The U.S. federal Office of Management and Budget’s PQC migration memo (OMB Memorandum M-23-02) requires agencies to designate accountable leads, submit cryptographic inventories on a recurring cadence through 2035, and submit associated funding assessments – turning “quantum readiness” into a recurring, auditable management system rather than a one‑off project. Even outside the federal context, this is a useful template for what “serious governance” looks like when a state actor treats the transition as mandatory.
What this means in schedule terms is simple: the six‑figure task count is often the shadow cast by the execution system itself – governance cadence, vendor enforcement, measurement, workforce absorption, ecosystem coordination – not just the crypto replacement work.
Vendor readiness is not a side quest; it’s frequently the critical path
The joint CISA / NSA / NIST quantum‑readiness factsheet treats vendor engagement as a core step of migration. It explicitly calls for discussing PQC roadmaps with vendors, ensuring contracts address PQC delivery expectations, and understanding dependencies across on‑prem COTS and cloud services. It even spells out “technology vendor responsibilities”: vendors should begin planning and testing integration and be ready to support PQC as soon as standards are finalized.
In a global enterprise, that translates into thousands of schedule tasks because vendor engagement is not one workshop – it becomes a lifecycle:
- classify suppliers by cryptographic criticality and “blast radius” across your service map
- run product‑by‑product roadmap reviews (not vendor‑level slide decks)
- update contractual language and enforceable delivery milestones
- coordinate joint pilots, interop testing, and production‑like validation
- align upgrades to change windows and outage constraints
- create escalation paths when a vendor cannot meet the timeline (including isolation, compensating controls, or replacement decisions)
That “vendor as a critical path constraint” is reinforced by national timelines that assume supplier dependency management as a first‑class deliverable. UK National Cyber Security Centre explicitly calls out supplier dependencies and instructs organizations to “communicate your needs to your suppliers,” while also expecting quantification and assurance as migration proceeds. The NSA’s CNSA 2.0 timelines show why: different technology categories have different target years for “support/prefer/exclusive,” and “custom/legacy” categories become waiver/replacement problems – not engineering wishfulness.
Reporting and metrics turn “readiness” into a living system – and that generates persistent work
Large programs either become measurable, or they become performative.
Multiple guidance streams expect quantification. UK guidance expects metrics good enough to quantify which clients are using PQC and identify those not using it – so you can eventually disable legacy support without breaking the business. OMB’s memo institutionalizes repeated reporting through recurring inventories and funding assessments, which makes progress auditable.
Those expectations generate task volume because measurement itself is work:
- design KPIs/KRIs that reflect both exposure and migration progress
- wire telemetry from inventories and configuration systems into dashboards
- build “coverage confidence” scoring (how sure are you that discovery is complete?)
- create audit evidence packs (what proves a system is actually quantum‑safe end‑to‑end?)
- maintain evergreen inventories as systems change (inventory as a living system, not a spreadsheet)
This is also where automation becomes central. The joint factsheet explicitly notes discovery tools may not detect embedded cryptography and instructs organizations to ask vendors for embedded crypto lists – creating an ongoing vendor‑evidence workflow. This is also where federal buyer guidance has begun to normalize Automated Cryptography Discovery and Inventory (ACDI) as a PQC use case: automation reduces manual workload, but it does not remove the need for governance, confidence scoring, and evidence discipline.
People and operating model are first‑order deliverables, not “soft” side work
Crypto migration can fail because the organization cannot absorb it.
NIST’s crypto‑agility maturity framing includes awareness and training as integral, and it emphasizes the need to continuously test practices so the organization can activate them when required. UK guidance also signals workforce capacity as a national constraint by discussing the assurance of consultancies supporting discovery and planning – a strong hint that skills availability is treated as a gating factor.
This is where “non‑crypto tasks” accumulate quickly:
- hiring and onboarding (plus access provisioning, lab environments, tool licensing)
- role‑based training for developers, architects, risk, procurement, OT engineers
- executive/board awareness loops tied to decision points and funding gates
- change‑management planning for process/tooling changes required for crypto agility
- exercises that test incident response and operational resilience under cryptographic stress
None of those tasks “replace RSA,” but without them, “replace RSA” does not happen safely.
Where the “other 90,000 tasks” comes from (high-level): In one large-enterprise model, only ~30,000 IMS tasks are “direct remediation packages” (the cutovers and deployments). The remaining ~90,000 tasks are the enablement system: inventory as a living capability, governance and reporting cadence, vendor lifecycle enforcement, testing/assurance, workforce change, ecosystem/partner alignment, and ongoing operations during the long hybrid period.
Illustrative task burden for the “enablement” domains (global enterprise, 8–12 workstreams, 7–10 year horizon):
- Governance + ERM integration: ~8,000–12,000 tasks
- Vendor lifecycle (classification → contracts → joint testing → upgrades → escalation): ~8,000–14,000 tasks
- Reporting + metrics + audit evidence + inventory “evergreen” upkeep: ~4,000–8,000 tasks
- Workforce + change management: ~5,000–10,000 tasks
- Ecosystem alignment (partners/sector coordination/interop forums): ~1,000–3,000 tasks
Illustrative allocation of 120,000 IMS tasks (example model, not a confidential plan). This is a model, not a claim that every enterprise will land on these numbers. Different organizations ‘bucket’ remediation differently. The point is not the exact split – it’s the fact that most of the schedule is enablement, not cipher‑suite edits.
| Category | What it covers (plain-English) | Tasks (sample) | Peaks in phase(s) | Why it multiplies |
|---|---|---|---|---|
| Governance, ERM, and IMS control | Program charter, steering cadence, risk register integration, issues management, streams and projects coordination, traceability management, decision forums, dependency management, WBS/IMS baselines, exception workflows, management of project professional services and tools, vendor management, engagement with stakeholders at the boundary – privacy, legal, customer support, marketing, PR, etc.; | 9,000 | All phases | Repeats weekly/monthly/quarterly across sub-programs for 7–10 years; every dependency change creates schedule maintenance work; major changes delivered by vendors require change requests; |
| Reporting, metrics, and audit evidence | KPIs/KRIs, dashboards, coverage confidence scoring, audit packs, “proof of quantum-safety” artifacts, evidence retention; reporting to risk committees, IA, various regulators; | 5,000 | Discovery → Operations | Measurement is a system: telemetry wiring, validation, recurring reporting cycles, auditor/regulator evidence expectations |
| Multi-modal discovery and “living” inventories | Network/endpoint discovery, source code and CI/CD crypto scanning, OT passive discovery, filesystems scanning, cloud discovery, API calls monitoring, runtime monitoring discovery, reconciliation into inventory/CBOM, tools and processes for CBOM maintenance; | 11,000 | Discovery (then ongoing) | No single modality sees all crypto; inventory drifts continuously; embedded crypto creates vendor-attestation workflows |
| Cryptographic strategy and pattern library | Approved mitigation patterns (PQC, hybrids, gateways, segmentation, replace/retire), decision tree, lab validation, exception policy | 7,000 | Assessment → Implementation | Every pattern must be validated and operationalized into reusable playbooks; exceptions and edge cases recur |
| Parallel Track 0: HNDL + TNFL burn‑down | Targeted re-encryption/re-wrapping, shorten trust lifetimes, protect signing chains and long-lived artifacts, priority channel hardening | 4,000 | Track 0 (then taper) | Immediate work across multiple domains; doesn’t wait for “main migration waves” |
| Infrastructure foundations | PKI rebuild and automation, HSM/KMS upgrades, trust stores, certificate profiles, network/middlebox readiness | 15,000 | Assessment → Implementation | PQC affects artifact sizes and traffic; shared infrastructure must be made crypto-agile before app waves |
| Testing, interoperability, and assurance | Labs, regression/perf/security testing, partner interop tests, failure-mode discovery (buffers, fragmentation), readiness sign-off | 14,000 | Assessment → Operations | PQC failures often appear only in integrated staging networks and multi-vendor chains; must be proven before scale-out |
| Vendor lifecycle and procurement enforcement | Supplier criticality classification, roadmap reviews, contract clauses, CBOM / embedded crypto attestations, joint pilots, upgrade planning, replacement procurement | 10,000 | Discovery → Implementation | Vendor readiness gates critical path; each product line + region + change window becomes a recurring dependency chain |
| Ecosystem and partner alignment | Inter-org / partner coordination, standards participation, bilateral/multilateral interop agreements, sector forums | 2,000 | Implementation (then ongoing) | No enterprise migrates alone; cross-organization interop and timing dependencies create persistent coordination tasks |
| Workforce and org change | Hiring, onboarding, role-based training, process/tooling changes for crypto agility, adoption support for engineering teams | 7,000 | Discovery → Implementation | Absorption capacity becomes the real bottleneck; change management repeats across domains and regions |
| Remediation execution waves | Repeatable remediation packages: upgrade/replace/wrap per service tier, cutovers, rollbacks, validation artifacts | 30,000 | Implementation (then tail) | Millions of crypto instances are grouped into packages; each package still requires full build/test/deploy/evidence cycles |
| Operations: monitoring, drills, and tech-watch | Continuous posture monitoring, crypto-policy enforcement, “agility drills,” incident exercises, standards watch | 6,000 | Operations (and ongoing) | Migration lasts long enough that drift is inevitable; dual/hybrid periods require sustained operational controls |
For example, even an ‘11,000 task’ discovery/inventory line item is not one activity: it is network protocol discovery, endpoint/server discovery, CI/CD and code/dependency scanning, OT passive discovery, vendor attestations for embedded crypto blind spots, data normalization/deduplication, and then repeated refresh cycles because the inventory changes continuously. Similarly, ‘hiring and upskilling’ is not one HR action: it is role definition, recruiting, onboarding/access provisioning, curriculum build, delivery across multiple stakeholder groups, and operating-model updates so the program can run for a decade.
A quick “roadmap vs. plan” gut-check (why real plans create task volume): Do we have an inventory that is broad (IT + OT + cloud + CI/CD) and deep (protocol/library/key/cert detail), and do we understand where automation is blind (embedded cryptography)? Is our migration strategy explicitly per service (in-place, re-platform, replace, compensate), and do we have rules for when each strategy is allowed? What is our hybrid strategy and terminology discipline (what do we mean by “hybrid,” where will we use it, and how will we phase it out)? Which vendor roadmaps are on our critical path, and what contract language forces delivery dates, test participation, and upgrade rights? Which parts of our identity and trust infrastructure (PKI, certificate lifecycle, HSM/KMS, code signing) need capacity and performance upgrades due to PQC artifact sizes and validation behaviors? What metrics will we report quarterly to prove progress without lying to ourselves (coverage, migration completion by criticality tier, residual exposure, supplier readiness, and “crypto agility maturity”)? If your organization answers these concretely, you should expect the task count to rise – because each “yes” implies an execution system.
Phase 0: The “Now” Tasks (HNDL & TNFL)
While the long-term migration plan is being built, a parallel workstream must launch immediately to address the risks that are already active. We call these the “Stop the Bleeding” tasks.
- Harvest Now, Decrypt Later (HNDL): Adversaries are stealing encrypted data today to decrypt it in the future. Mitigating this requires re-encryption campaigns for long-retention data (e.g., changing AES modes or increasing key sizes where PQC isn’t yet an option) and implementing strict forward secrecy.
- Trust Now, Forge Later (TNFL): As discussed in my article on Trust Now, Forge Later, long-lived digital signatures on documents (mortgages, wills, contracts) could be forged by future quantum computers. We must identify these static assets and apply timestamping authorities or wrap them in quantum-safe archival containers now.
This also involves immediate policy changes: shortening certificate lifespans to reduce exposure windows and rewriting vendor contracts to mandate future PQC compliance. These are not “planning” tasks; they are immediate remediation actions that add thousands of lines to the schedule in Year 1.
In an IMS, this Track 0 work commonly consumes ~2,000–6,000 tasks on its own – not because it replaces migration, but because it is a parallel portfolio of targeted controls executed across multiple trust domains, datasets, and product teams. (In the allocation table above, it is represented as a ~4,000-task category within the overall 120,000.)
Phase 1 – Discovery
Discovery alone generates thousands of tasks. You need automated network scanning, CMDB reconciliation, procurement record analysis, interviews with facility managers, and manual site walkthroughs – for every location.
You need code and configuration analysis scanning source code for cryptographic API calls, digital certificate inventories, network traffic analysis to identify crypto in use, vendor documentation reviews, and stakeholder surveys – for every application.
The Keyfactor 2023 State of Machine Identity Report found that enterprises average 256,000 internally trusted certificates managed across an average of 9 PKI and CA solutions. Each certificate must be catalogued, mapped to a system, classified by algorithm type, and assessed for quantum vulnerability. IBM’s research shows non-human identities – service accounts, API keys, machine certificates – now outnumber human identities by at least 40 to 1, CIO and CyberArk’s 2025 data suggests the ratio may exceed 82:1. Each non-human identity represents a cryptographic dependency that must be discovered, documented, and eventually migrated.
For a large telecom operator, discovery is not a single scan-and-done exercise. It spans IT systems (thousands of applications, databases, middleware platforms), network infrastructure (radio access networks, transport, core, IMS, OSS/BSS), operational technology (power management, cooling, physical security, environmental monitoring), and cloud/SaaS integrations. Building the Cryptographic Bill of Materials – the CBOM – requires mapping every cryptographic algorithm, every key, every certificate, every cryptographic library and module, every protocol and its configuration, and every dependency relationship. The OWASP CycloneDX 1.6 specification, which formalized native CBOM support in 2024, defines distinct data objects for algorithms (including variant, mode, padding, key length, and NIST quantum security category), keys (type, size, format, storage method, lifecycle status), certificates (subject, issuer, validity, public key algorithm), libraries (version, FIPS certification status), and protocols (cipher suites, configuration parameters). This is not a spreadsheet. It is a living data model that must be built from source code analysis, binary scanning, dependency metadata, configuration file parsing, and runtime dynamic discovery across every layer of the enterprise.
Task-count consistency note: the initial Discovery phase sprint (Year 0–1) typically generates ~2,000 to 5,000 tasks in program plans, because you are standing up the discovery machinery and delivering the first defensible inventory. But over the full 7–10 year horizon, the “discovery + living inventory” workstream is much larger (represented as ~11,000 tasks in the allocation table) because inventories must be continuously refreshed, reconciled, and integrated into CI/CD, asset management, and change control.
It requires a team of 5 to 15 people working for 6 to 12 months, at a cost of roughly $2 to $5 million for a large enterprise.
Phase 2 – Assessment and Planning
Assessment and Planning multiplies the task count further. Every discovered cryptographic instance must be classified by vulnerability type (quantum-vulnerable asymmetric, secure-but-needs-larger-key symmetric, or non-cryptographic hash), by the sensitivity of the data it protects, by the longevity of confidentiality requirements, and by exposure level (internet-facing versus internal).
A risk-based prioritization then segments instances into tiers – perhaps 100 “Tier 1” assets protecting crown jewels (customer PII, inter-carrier signaling, payment systems), a few hundred Tier 2 assets, and thousands of Tier 3 assets.
Those tiers are not just a reporting artifact – they are the input to a cryptographic decision factory. Once you’ve classified and prioritized, the program has to translate “millions of cryptographic dependencies” into a finite set of approved mitigation patterns, sequencing rules, and implementation playbooks that engineering teams can execute repeatedly without re-arguing architecture every time.
What comes after inventory is where many programs discover the real bottleneck: cryptographic strategy. A CBOM (or any cryptographic inventory) tells you what exists and where it exists. It does not tell you what to do about it. Translating “millions of quantum-vulnerable cryptographic dependencies” into a finite set of implementable, schedulable migration actions is its own major workstream – often the workstream that determines whether your implementation wave plan is realistic or fantasy.
In practice, a cryptographic strategy is not just an “algorithm selection” document. It is a decision framework plus a library of repeatable mitigation patterns that teams can apply consistently across thousands of systems while preserving operations. That is the essence of crypto-agility: the capability to replace cryptography across protocols, applications, hardware/firmware, and infrastructure without breaking the business.
Here is the uncomfortable reality: for a large estate, “PQC upgrade” is only one of several legitimate mitigations, and you often need multiple mitigations in parallel. A strategy typically has to define (at minimum) patterns like these, along with the rule-set for when each pattern is allowed:
- Direct PQC upgrade. Replace quantum-vulnerable public-key mechanisms with standardized post-quantum mechanisms as supplier support and assurance becomes available (and as testing confirms operational fit).
- Interim or persistent hybrid approaches. Hybrids are not a single approach; they are a family. Hybrid key establishment (PQ + classical) differs from hybrid authentication/signatures, and differs again from “hybrid-at-the-edge” designs where a gateway terminates PQC externally but speaks classical internally. The terminology and the need for consistent language here is now formalized in an IETF RFC specifically about PQ/T hybrid schemes.
- Cryptographic gateways / crypto proxies. Where systems can’t be upgraded in time (or can’t be upgraded at all), strategy must define when you are allowed to wrap legacy protocols in a quantum-resistant envelope at a boundary – especially in OT/ICS and in long-lifecycle embedded environments. That is not “avoiding migration”; it is a controlled time-buying measure that creates its own security and operational requirements.
- PFED-style protocol-independent encryption. In some constrained or fragile environments, teams explore drop-in encryption devices that can protect traffic without requiring protocol changes in legacy endpoints. Whether you call it PFED or “inline encryptors,” the strategic point is the same: the mitigation sits outside the application, so the task model shifts from software remediation to hardware lifecycle management (procurement, install, keying, monitoring, spares).
- De-exposure via isolation and segmentation. Sometimes the rational path is not “upgrade now,” but “reduce reachable attack surface now” by segmentation, boundary controls, and containment – while you wait on vendor roadmaps or replacement cycles. Several national transition frameworks explicitly treat triage as risk-based and recognize the role of non-cryptographic protections and system lifecycle constraints in determining transition order.
- Risk-shaping through data minimization and tokenization. For certain data classes, you can materially reduce HNDL impact by storing less sensitive material (or storing sensitive identifiers as tokens), shortening retention windows, and re-architecting flows so that intercepted ciphertext is less valuable even if decrypted later. This is not “crypto work,” but it is absolutely quantum-risk work – and it belongs in the cryptographic strategy decision model so it can be scheduled and governed like everything else.
- Replacement or retirement of non-upgradable systems. Your strategy must declare the criteria for “upgrade vs. mitigate vs. replace,” because many environments – especially OT/IoT and legacy vendor appliances – simply won’t be convertible to PQC in place. Multiple migration handbooks explicitly warn that not all PQC solutions fit all scenarios and that strategy may require new hardware or even switching vendors, which is precisely why this decision work becomes a major schedule driver.
In an IMS, cryptographic strategy becomes thousands of real tasks because it is a production decision factory: building the decision tree, defining approved patterns, running lab experiments to validate performance and interoperability, negotiating “support statements” from vendors, defining exception policies, and creating implementation playbooks that allow engineers to execute repeatedly without re-litigating the same architectural debates for every system.
Phase 2 typically adds another 3,000 to 8,000 tasks – because turning inventory into repeatable mitigation patterns is where the program’s real decision load lives. (In the allocation table above, this “strategy/pattern library” work is represented as ~7,000 tasks across the full horizon.)
Phase 3 – Implementation
Implementation is where the numbers explode. This phase consumes 80 to 90 percent of the total program budget and runs for seven or more years in a large enterprise.
- Every application using quantum-vulnerable cryptography needs code changes, library updates, configuration modifications, and testing – unit testing, integration testing, performance testing, security testing, and regression testing.
- Every network element using IPsec, TLS, or SSH needs firmware or software updates, configuration changes, and interoperability testing with every other element it communicates with.
- Every PKI hierarchy needs new certificate authorities, new certificate profiles supporting PQC algorithms, new certificate lifecycle management processes, and migration of issued certificates.
- Every HSM may need firmware updates or hardware replacement to support PQC key generation and storage – and FIPS 140-3 validation/certification cycles for new configurations can be long, which turns “crypto upgrade” into a procurement-and-certification scheduling problem as much as a technical one.
- And so on.
Consider the PKI dimension alone. A three-certificate chain using ML-DSA can be multiple times larger than an equivalent ECDSA chain, which stresses repositories, revocation infrastructure (CRL/OCSP), and relying-party parsing limits. Certificate template updates, issuance workflow changes, revocation process updates, and automated renewal pipeline modifications each become distinct tasks. Importantly: the IMS does not count “one task per certificate.” It counts the automation build-out plus the certificate migration waves needed to move hundreds of thousands of certificates safely across multiple PKI stacks.
The network impact layer adds another dimension. If you want the deeper engineering story behind why ‘turning on PQC’ breaks real networks – fragmented handshakes, QUIC initial packet behavior, middlebox ossification, and latency cliffs – see my companion deep dive on infrastructure challenges of ‘dropping in’ PQC. Hybrid TLS 1.3 handshakes can add on the order of ~10 KB (or more) of additional cryptographic material depending on configuration and certificate chain size. The IETF’s TLS hybrid key exchange draft defines X25519MLKEM768 client shares at 1,216 bytes versus 32 bytes for X25519 alone – roughly 38 times larger. ML-DSA-65 signatures are approximately 3,293 bytes versus 64 bytes for ECDSA P-256 – more than 50 times larger. This cascades through every network element: firewalls with fixed buffer sizes, middleboxes performing deep packet inspection, load balancers, WAFs, API gateways, and proxies – each of which may need configuration changes, firmware updates, or replacement. Google and Cloudflare found during early PQC testing that “a lot of buggy code” in middleboxes broke with unexpectedly large keys. Under simulated low-bandwidth conditions, PQC handshakes measurably slowed TLS 1.3; in lossy network conditions, the slowdown worsened further.
This is why programs end up with entire testing workstreams: you can’t spreadsheet your way out of handshake fragmentation and buffer cliffs – you have to reproduce them in representative staging networks, pressure vendors, and then redesign rollout waves accordingly.
For each remediation package (not each individual crypto finding), the implementation tasks typically include: cryptographic library assessment and upgrade, code or configuration changes for new algorithm APIs, certificate/profile updates where applicable, key rotation procedures, unit testing, integration testing with dependent systems, performance testing under production-like load, security assessment, rollback procedure development, production deployment planning, staged rollout execution, post-deployment monitoring, evidence capture, and documentation updates. That is roughly 15 to 25 IMS tasks per remediation package. In a large enterprise, you may end up with hundreds to a few thousand such packages spanning application tiers, network domains, regions, and vendor stacks – which is how a remediation “waves” category can land in the ~20,000-task range without counting every certificate or every endpoint as a separate task.
Applications are only one vector. Network infrastructure elements add similar per-domain task chains. IoT and OT devices add constrained-environment handling. Vendor-dependent systems add coordination tasks. Each workstream generates its own project management, governance, reporting, and change management overhead.
A more honest breakdown: remediation is only about a sixth to a third of the IMS (depending on how organizations bucket work). The critical misunderstanding behind most skepticism about “120,000 tasks” is the belief that the schedule is a giant list of crypto fixes. In reality, a mature plan treats individual crypto findings as inputs to triage. The execution unit is a remediation package (a category) defined by criticality, mitigation pattern, dependency chain (vendors/partners), environment (cloud/on-prem/edge/OT), and deployment wave. That design is what allows millions of cryptographic dependencies to be grouped into a manageable set of repeatable work packages.
When you do that, remediation is often only ~15–40% of the integrated schedule. The remaining majority is the scaffolding that makes remediation possible: multi-modal discovery and continuous inventory, cryptographic strategy decision-making, infrastructure readiness (PKI/HSM/KMS/network), vendor and contract work, testing and assurance, training and organizational change, operational monitoring, and governance/reporting over a decade-long horizon. Those categories are not optional overhead; they are explicitly embedded across the major national transition frameworks and government mandates (inventory, triage, implementation planning, vendor engagement, and continuous monitoring).
That reaches 120,000. And this is not a padded estimate. Each line represents irreducible work. If you remove any of these dimensions, you create gaps that will surface as failures during deployment – broken integrations, incompatible protocols, expired certificates, performance degradation, compliance violations, or security vulnerabilities.
The operational technology problem nobody wants to talk about
The IT migration is enormous. The OT migration may be impossible on the timelines regulators are demanding.
Operational technology environments – industrial control systems, SCADA, building management, power distribution, medical devices, manufacturing systems – face a set of constraints that make PQC migration qualitatively different from IT migration. OT components routinely operate for 10 to 20+ years. Nuclear plant control systems, power grid SCADA networks, and hospital medical devices may be running on hardware designed decades ago. Many use 8-bit or 16-bit microcontrollers with very limited RAM and flash – often orders of magnitude less than modern IT endpoints. PQC algorithms have larger key and signature sizes and can require multiple kilobytes of working buffers in constant-time implementations – which is a non-trivial constraint in embedded environments.
Patching windows in OT are measured in months, not days. A programmable logic controller managing a production line or a safety instrumented system in a chemical plant cannot be taken offline for a software update without extensive pre-testing, safety analysis, and sometimes regulatory recertification. Medical device firmware changes may require FDA resubmission. Avionics modifications require aviation authority approval. Some OT devices simply cannot be updated at all – they lack over-the-air firmware update capabilities and were never designed for cryptographic algorithm replacement.
The cryptographic use cases in OT are particularly sensitive. Firmware signing ensures that only authenticated code runs on controllers that manage physical processes. Device authentication prevents unauthorized access to systems that control power grids, water treatment, and manufacturing equipment. VPN connections protect the control channels through which operators issue commands to physical infrastructure. If any of these cryptographic protections fail – or if they are broken by a quantum-capable adversary – the consequences are not data breaches. They are physical destruction, environmental damage, and potential loss of life.
The strategies for OT migration are workarounds, not solutions: crypto-agile gateways that add a quantum-resistant envelope around legacy protocol traffic, hybrid certificates where devices can support them, network segmentation to limit quantum attack surfaces, and ultimately hardware replacement for devices that cannot be upgraded. Each strategy adds complexity. Gateways must be deployed, configured, tested, and maintained at every boundary between OT and IT networks. Segmentation requires network architecture redesign. Hardware replacement requires procurement, installation, commissioning, and recertification – often for equipment that was specified years in advance and has multi-year lead times.
In our telecom program plans, the OT layer – power management systems, cooling infrastructure, physical security, environmental monitoring, tower equipment – generates roughly 15 to 20 percent of total program tasks despite representing a much smaller fraction of the overall IT asset count. The per-asset task cost for OT migration is three to five times higher than for standard IT applications because of the safety analysis, vendor coordination, extended testing, and constrained deployment windows involved.
Low-power IoT turns migration into a physics problem
If OT is difficult, low-power IoT is in many cases currently impossible with existing PQC algorithms. The PQC network impact analysis reveals a hard constraint: current PQC algorithms are unusable in many IoT systems.
Consider LoRaWAN, one of the most widely deployed LPWAN technologies. A single LoRaWAN frame carries a payload of 51 bytes in EU regions or 11 bytes in the US, subject to a 1 percent duty cycle. A PQC key exchange requiring 1.5 KB plus a 2 KB certificate signature would need dozens of LoRaWAN frames to complete – a process that could literally take hours. Sigfox limits payloads to 12 bytes. NB-IoT operates at tens of kilobits per second, where transmitting kilobyte-scale PQC handshake data significantly increases both transmission time and energy consumption. For battery-powered sensors with multi-year deployment lifetimes, the additional energy cost of PQC handshakes could reduce operational life by months or years.
The 6TiSCH protocol, used in industrial IoT mesh networks, has a maximum frame size of 127 bytes with approximately 45 bytes of net payload in multi-hop configurations. Fitting PQC cryptographic material into these constraints requires either protocol redesign, compression techniques that are still in research, or a fundamentally different approach to securing constrained networks.
Large enterprises may operate hundreds of thousands or millions of IoT devices across facilities, campuses, and remote installations. Each device category requires its own migration analysis, and for many categories, the answer will be: this device cannot support PQC and must either be replaced, isolated, or protected by an intermediate gateway. Each of these decisions becomes a task tree in the program plan: assess device capability, evaluate replacement options, design isolation or gateway architecture, procure replacement or gateway hardware, deploy, configure, test, validate, document.
The risk of a naive approach is real. As the network impact analysis warns: “turning on PQC everywhere” could unintentionally cut off low-power sensors, creating blind spots in environmental monitoring, industrial process control, or safety systems. The same infrastructure theme repeats here: protocols and devices were built with implicit size/latency assumptions, and PQC pressure-tests those assumptions in constrained networks – meaning your ‘IoT plan’ becomes a device-family-by-device-family engineering and procurement program, not a config change. The migration program must identify these constraints early and plan around them – which means the discovery and assessment phases must reach into every corner of the network, including devices that IT may not even know exist.
Your vendors are not going to save you
The finding that 62% of organizations expect their vendors to handle the quantum-safe transition reveals a profound misunderstanding of the problem. Vendors will, eventually, ship PQC-capable products. Some already have. CISA’s January 2026 product categories publication provides one view of where PQC-capable offerings are emerging in the commercial ecosystem. But “PQC-capable” in procurement language does not automatically mean “end-to-end quantum-safe” in your environment – especially while many products prioritize key establishment first and signatures/authentication later.
More fundamentally, your vendors shipping PQC-capable products is necessary but nowhere near sufficient. Your organization must still discover which products are in use, determine which versions support PQC, test PQC configurations against your specific environment and integrations, coordinate upgrade timelines across interdependent systems, manage configuration changes across thousands of instances, handle edge cases where vendor PQC support is incomplete or incompatible with other vendors’ implementations, and verify that the entire chain – from your application through middleware through network infrastructure through the vendor’s service – is quantum-safe end to end.
The vendor supply chain dimension generates its own task multiplication. A large telecom operator works with hundreds of technology vendors. Each vendor has its own PQC roadmap – or lacks one. The GSMA Post-Quantum Telecom Network Task Force, comprising over 50 organizations including 20+ major network operators, GSMA has published guidelines for quantum risk management and PQC use cases, but adoption is uneven. Each vendor relationship requires: assessing the vendor’s PQC readiness, demanding Cryptographic Bills of Materials (CBOMs), requiring PQC-upgradability clauses in contracts, testing vendor-supplied PQC updates in lab environments, coordinating deployment windows, and maintaining fallback plans for vendors that cannot deliver on time.
For custom-built and legacy systems – which the CISA/NSA/NIST joint quantum readiness factsheet identifies as likely requiring “the most effort” – there are no vendor solutions at all. The organization must modify, wrap, or replace these systems using internal resources. Legacy applications often lack comprehensive documentation of their cryptographic dependencies, use deprecated libraries, or embed hard-coded algorithm references that require code-level remediation.
There is also a class of risk that doesn’t show up in vendor ‘roadmaps’ at all: orphan products. Over a 7-10 year horizon, some vendors will discontinue platforms, merge, or stop supporting the versions you run. For regulated or safety‑critical systems, the remediation path can become legal as much as technical: triggering escrow clauses to obtain source code, negotiating support extensions, or deciding whether to isolate, wrap, or replace. Those decisions are not edge cases in long migrations – they are predictable workload.
The interconnected ecosystem extends beyond direct vendors to their subcontractors, creating “n-th party quantum risk.” An enterprise’s cloud provider depends on its own hardware vendors, OS suppliers, and networking equipment manufacturers. A payment processor depends on its card network, its HSM vendor, and its connectivity provider. Each link in this chain uses cryptography, and a quantum-vulnerable link anywhere in the chain creates exposure for every organization that depends on it. Contractual agreements must address this. Contingency plans must account for vendors that are not ready on time. Quantum readiness assessments must extend to key third parties. Each of these requirements generates work packages in the program plan.
Interoperability is also a people problem. In multi‑vendor stacks, the program team often has to broker joint testing across suppliers – sometimes between competing vendors – to avoid ‘PQC works in isolation’ failures. That interop diplomacy becomes its own workstream: lab environment agreements, shared test vectors, partner/customer pilot coordination, defect triage across vendor boundaries, and escalation when one side lags. (In the 120,000-task allocation, this shows up primarily in the “Testing/interop/assurance” and “Ecosystem/partner alignment” categories.)
The CBOM imperative and why it changes everything
The Cryptographic Bill of Materials (CBOM) is the foundation on which the entire migration program rests, and it is also one of the most underappreciated sources of program complexity.
A CBOM is a structured inventory describing all cryptographic assets in a system and their relationships. It is to cryptography what an SBOM is to software components. The OWASP CycloneDX project formalized CBOM support in version 1.6, released in 2024 and ratified as ECMA-424 at the 127th Ecma General Assembly. The EU’s coordinated PQC implementation roadmap explicitly states that organizations should maintain cryptographic inventories using standardized formats including CBOM – one of the first policy-level references to CBOM by name. India’s quantum-safe roadmap makes CBOM submissions mandatory from FY 2027-28. Australia’s ASD guidance mandates CBOM as part of PQC transition planning.
Inventorying cryptography and building a comprehensive CBOM requires data from multiple sources: static source code analysis scanning for cryptographic API calls, constants, and patterns; binary and bytecode analysis scanning compiled software for cryptographic signatures; dependency and package metadata mapping software components to their cryptographic libraries; configuration file analysis extracting TLS settings, keystore files, and properties; and runtime dynamic discovery using network traffic analysis and hooking to identify cryptography in actual use. Tools exist, but no tool provides complete coverage. Building the CBOM for a large enterprise requires combining automated tooling with manual code reviews, vendor documentation analysis, and continuous updates as the environment changes.
The CBOM is not a one-time artifact. It is a living document that must be version-controlled, change-tracked, and continuously regenerated. Every software release, firmware update, configuration change, and new vendor integration potentially alters the cryptographic inventory. CI/CD pipeline integration – generating and validating CBOMs as part of every build – becomes a requirement, adding tasks to every development team’s workflow.
The CBOM also enables the next phase: risk assessment. Without knowing precisely what cryptography exists where, you cannot prioritize. Without prioritization, you cannot build a credible migration roadmap. Without a roadmap, you cannot estimate costs, secure budgets, allocate resources, or demonstrate progress to regulators. The CBOM is not bureaucratic overhead. It is the enabling prerequisite for every subsequent program activity.
Phase by phase: where the years go
Understanding the program’s temporal structure helps explain why timelines stretch to a decade or more and task counts reach six figures. (Illustrative)
Year 0-1: Initiation and Discovery
Secure executive mandate and budget. Establish program governance – steering committee, program management office, workstream leads. In practice, this needs a single accountable enterprise lead – call it a PQC Migration Lead or ‘PQC Czar’ – with authority across security, IT, engineering, procurement, and OT. Without that role, cryptography stays ‘everywhere’ and therefore owned by no one.
Begin comprehensive asset discovery across IT, OT, cloud, and IoT environments. Launch cryptographic inventory development.
Engage key vendors for initial PQC roadmap assessments. Conduct initial awareness training for leadership and technical teams. Deliver Phase 1 outputs: complete asset list, detailed cryptographic algorithm and key catalog, classification of every instance by function, business impact, and vulnerability type, and identification of high-risk items.
Cost: $2–5 million. Team: 5–15 people.
Parallel Track 0
Immediate risk burn-down for HNDL and TNFL. While the enterprise-wide migration plan ramps up, most large organizations should start day one with a “do-no-regrets” set of actions aimed at the two time-asymmetry threats: Harvest Now, Decrypt Later (HNDL) and Trust Now, Forge Later (TNFL). Government guidance explicitly warns that encrypted data can be recorded now and decrypted later, which means “waiting for full migration” is not a risk-neutral choice for long-secrecy data.
In practice, this parallel track turns into thousands of tasks because it is not a single control – it’s a portfolio of targeted interventions. For HNDL, that can include prioritizing the most secrecy-sensitive data flows and stores (long-lived PII, strategic IP, sensitive customer records), shortening retention where feasible, re-encrypting high-value archives under fresh key hierarchies, and accelerating quantum-safe or hybrid protections on the most exposed external channels ahead of broader rollout waves.
For TNFL, the early actions are different: you are protecting the “roots of trust” that will matter later – software/firmware signing chains, long-lived certificates, critical audit logs, and long-validity signed artifacts. That often translates into shortening certificate lifetimes for high-risk trust domains (and investing in automation – because the industry is moving toward dramatically shorter public TLS certificate validity windows anyway), re-signing or time-stamping certain high-value archives, accelerating PQC planning specifically for code-signing and identity PKI, and hardening the processes that prevent forged trust artifacts from being accepted at scale.
This isn’t a speculative ‘quantum-era nice-to-have’: the CA/Browser Forum has already adopted a phased schedule that reduces maximum publicly trusted TLS certificate validity to 47 days by March 2029 – effectively making automated certificate lifecycle management table-stakes.
IMS impact: Track 0 can be ~2k-6k tasks (illustrative: re-encrypt archives; automate rotation; re-sign/time-stamp artifacts).
Year 2–3: Assessment, Strategy, and Early Pilots
Complete risk-based prioritization of all discovered cryptographic instances. Define cryptographic strategy: algorithm choices (ML-KEM-768 or ML-KEM-1024 for key encapsulation, ML-DSA-65 or ML-DSA-87 for signatures, hybrid configurations for transition), migration patterns for each system category, handling strategies for unpatchable systems. Update policies and governance frameworks. Launch pilot implementations on non-critical systems. Test hybrid VPN configurations, hybrid TLS deployments, PQC certificate issuance from test CAs. Validate performance impacts – confirming or revising assumptions about handshake latency, bandwidth consumption, and computational overhead. Begin PKI infrastructure planning for PQC root and intermediate CAs.
Cost: $1–3 million for assessment, plus early pilot costs. Team: 5–10 core, expanding to 20+ for pilots.
Year 4–5: Core implementations begin (Wave 1)
Migrate highest-priority systems: PKI infrastructure, VPN gateways, authentication servers, data encryption for long-lived sensitive data. Deploy PQC-capable HSMs (which may require long procurement-to-validation cycles depending on regulatory constraints). Begin systematic remediation for Tier 1 systems. Coordinate with critical vendors for infrastructure updates. Establish dual-stack (hybrid) operations where full PQC migration is not yet possible.
This is where the task count begins to accelerate dramatically, as parallel workstreams operate across infrastructure, applications, network, vendor coordination, PKI, and testing simultaneously.
Year 6-8: Broad rollout (Waves 2 and 3)
Migrate Tier 2 and Tier 3 systems. Scale remediation across the full portfolio. Complete network infrastructure upgrades – firewalls, load balancers, proxies, middleboxes. Address OT systems through gateway deployment, segmentation, or hardware replacement. Manage IoT device category-by-category migration or isolation. Coordinate with external partners, standards bodies (3GPP, GSMA, IETF), and regulators. Peak staffing: 50+ people. This phase typically represents the majority of program tasks and budget.
Cost: potentially hundreds of millions of dollars for a large enterprise – 80 to 90 percent of total program spend.
Year 9-10: Final phase and flag-day transitions
Complete migration of remaining systems. Execute “flag day” transitions where simultaneous cutover is required (e.g., lawful interception systems, bilateral key management with partners). Conduct comprehensive testing and validation of end-to-end quantum safety. Address residual legacy systems through isolation or retirement. Document compliance evidence for regulators and auditors.
Year 11+: Ongoing evolution
Continuous monitoring of quantum computing advances. Algorithm agility maintenance – NIST has already selected HQC as an additional KEM standard, and FIPS 206 (FN-DSA, derived from FALCON) is in development. Crypto-agility drills. Performance tuning and optimization. Compliance reporting.
The U.S. federal government has publicly discussed PQC migration cost at the multi-billion-dollar level through 2035 across federal agencies. For a single large telecom operator, our cost models range from $50 million to $300+ million over the program’s lifetime, depending on network size, legacy burden, and the proportion of systems requiring hardware replacement versus software updates.
The skills gap is a timeline multiplier
Every phase of the program requires skills that most organizations do not currently possess in adequate numbers. The IBM Quantum-Safe Readiness Index signals that expertise is a constraint, and the Enterprise PQC Migration Study notes that skilled PQC personnel are scarce globally and unevenly distributed. Multinational enterprises also face additional delays for globally synchronized deployment across regions, vendors, and regulatory regimes.
The skill domains required span program governance and strategy, cryptographic discovery and CBOM development, PKI and key management engineering, protocol and application engineering, security assurance and testing, data governance and compliance, and procurement and vendor management. Each domain requires distinct expertise. Program governance needs strategic thinkers who can translate quantum risk into business impact and maintain multi-year executive commitment. Cryptographic discovery needs investigators who combine automated scanning skills with deep understanding of how cryptography is implemented across diverse technology stacks. PKI engineering needs specialists who understand X.509 certificate formats, CA hierarchy design, HSM operations, and the specific implications of PQC for certificate chain sizes, revocation infrastructure, and key lifecycle management. Protocol engineering needs developers who can integrate PQC libraries into applications, tune TLS and IPsec configurations, and handle backward compatibility during hybrid operation.
The encouraging reality is that most of these skills can be developed from existing staff with targeted training and clear mandates. You do not need deep quantum physics knowledge or advanced mathematics. But you do need to invest in upskilling, and you need to start now – because training takes time, and trained people cannot be created on demand when the program hits peak staffing in years 4 through 8.
The organizational challenge extends beyond skills to structure. PQC migration cuts across every traditional organizational boundary: IT, network engineering, security, risk management, legal, procurement, compliance, facilities management, and operations. No single team owns cryptography in most enterprises. Creating the cross-functional governance structure to coordinate a decade-long program across all of these stakeholders – and sustaining it through leadership changes, budget cycles, and competing priorities – is itself a significant management challenge.
Hybrid operations add overhead, not simplicity
Hybrid cryptography – running classical and PQC algorithms simultaneously – is universally recommended as a transitional approach. The IETF formalized terminology for these schemes in RFC 9794 (June 2025), defining “PQ/T hybrid” approaches that combine post-quantum and traditional algorithms. The UK NCSC, EU roadmap, and NIST all endorse hybrid modes during transition. The logic is sound: hybrid provides protection against both quantum attacks (via the PQC component) and potential weaknesses in new PQC algorithms (via the classical component).
But hybrid operation is not free. It creates what the Enterprise PQC Migration Study calls “zombie algorithms” – RSA and ECC becoming cryptographically obsolete yet operationally alive. Based on the IPv4/IPv6 dual-stack experience, hybrid operation adds overhead to network operations and cryptographic operations staff time during the transition period, driven by maintaining, monitoring, and patching two sets of algorithms rather than one.
Every system running in hybrid mode requires more testing – classical-only fallback must work, PQC-only must work, and the hybrid combination must work. Configuration management expands. Certificate management becomes more complex as systems may need to present hybrid certificates containing both classical and PQC keys and signatures. Some applications cannot tolerate the additional latency or bandwidth of hybrid handshakes, requiring optimization or exemptions.
Long migrations also require rehearsals. If credible quantum capability emerges earlier than expected, the organization needs practiced decision paths: what gets accelerated, what gets isolated, what gets shut down, and what gets communicated externally. Regular ‘quantum fire drills’ – tabletops plus technical readiness exercises – turn that into muscle memory. They also surface whether your ‘evergreen inventory’ is actually usable under pressure. In the 120,000-task allocation model, these drills and exercises are part of the ongoing “Operations: monitoring, drills, and tech-watch” workstream.
In the program plan, hybrid operation does not reduce the task count. It adds a layer of tasks – configuration, testing, monitoring, and eventually sunset of the classical component – on top of the base migration tasks. It is the right approach for managing transition risk, but it should not be confused with simplification.
The Capgemini data confirms we are not ready
The Capgemini Research Institute’s “Future Encrypted” report, published in July 2025 from a survey of 1,000 organizations with $1 billion or more in revenue across 13 sectors and 13 countries, provides the most comprehensive current snapshot of enterprise quantum readiness. The findings are sobering.
65 percent of organizations are concerned about harvest-now, decrypt-later attacks. 70 percent are at least assessing or deploying quantum-safe measures. But only 15 percent of these early adopters – roughly 11 percent of the total sample – qualify as “quantum-safe champions” with mature governance and technical execution. Approximately 50 percent of early adopters are running PQC pilots, but few have a clear enterprise-wide roadmap. 30 percent of organizations still downplay the urgency entirely. And 70 percent say regulatory mandates – not threat awareness – are the primary driver behind their PQC adoption efforts.
This data tells a story of fragmented, bottom-up experimentation without the programmatic structure needed to reach completion. Running a PQC pilot on a single VPN gateway is a different activity than building a 120,000-task integrated program plan. The gap between them is the gap between a proof of concept and a production deployment, multiplied by every system in the enterprise.
The industry needs to move from pilots to programs. And programs of this scale require the disciplines of large-scale program management: integrated master schedules, work breakdown structures, critical path analysis, earned value management, resource leveling, risk registers, and governance frameworks. The GAO’s Schedule Assessment Guide identifies ten best practices for reliable project schedules – capturing all activities, sequencing them logically, assigning resources, establishing realistic durations, ensuring traceability, validating the critical path, maintaining a baseline, conducting schedule risk analysis, reflecting current status, and ensuring high confidence. The Department of Energy’s integrated master schedule guidance emphasizes that the IMS should be based on critical path method scheduling, contain all networked detailed tasks, and be traceable to the work breakdown structure.
These are the disciplines that differentiate a credible migration program from a wishful timeline on a PowerPoint slide. They are also the disciplines that, when applied rigorously to the scope of PQC migration, generate an honest task count in the six-figure range.
How to approach a program of this scale
Acknowledging the scale is not the same as being paralyzed by it. Organizations that are making genuine progress share several common characteristics.
They start with executive mandate and multi-year budget commitment. PQC migration spans multiple budget cycles, multiple CIO/CISO tenures, and multiple technology generations. Without board-level understanding and commitment – not just awareness, but budgeted commitment – the program will stall during its first budget review. Mosca’s inequality provides the framing: if the time your data needs to remain secure (X) plus the time it will take to migrate (Y) exceeds the time until quantum computers can break your encryption (Q), then you are already late. For most large enterprises, X + Y > Q is already true.
They treat discovery as an ongoing capability, not a one-time project. The cryptographic inventory is never complete, because the enterprise is never static. New applications deploy, new vendors onboard, new IoT devices connect, new services launch. The CBOM must be continuously regenerated, validated, and reconciled with the asset inventory. Organizations that build discovery into their CI/CD pipelines and change management processes will have a current, accurate picture of their cryptographic exposure. Those that treat it as an annual audit will always be operating on stale data.
They prioritize ruthlessly based on risk. Not every system needs to be migrated simultaneously. The harvest-now, decrypt-later threat means that systems protecting long-lived sensitive data – healthcare records, classified information, intellectual property, financial instruments with multi-decade lifetimes – should be prioritized first. Critical infrastructure systems where quantum-enabled compromise could cause physical harm should be next. Commodity IT systems protecting transient data can follow. This risk-based approach allows the program to deliver meaningful security improvements in years 1 through 3 while the broader migration continues through year 10 and beyond.
They build crypto-agility as a design principle, not just a migration tactic. The concept I have semi-jokingly formalized as Marin’s Law states that migration time (Y) is approximately proportional to the ratio of cryptographic instances (K) to crypto-agility (A): Y ≈ K/A. As crypto-agility approaches zero – as it does in most current enterprise environments – migration time approaches infinity. Organizations that invest in crypto-agile architecture now – abstracting cryptographic operations behind configurable APIs, separating policy from mechanism, enabling algorithm swaps without application changes – will not only migrate to PQC faster but will be prepared for the next cryptographic transition, whatever it may be. NIST’s CSWP 39, finalized in December 2025, provides comprehensive guidance on achieving crypto-agility, emphasizing API abstraction, policy-mechanism separation, machine-readable configuration profiles, and continuous crypto risk assessment.
They engage the ecosystem. No organization migrates alone. The GSMA Post-Quantum Telecom Network Task Force provides a model for sector-level coordination. The BIS roadmap emphasizes system-wide stress testing across financial institutions. Industry ISACs enable threat intelligence sharing. Vendor engagement starts early and operates as an ongoing conversation rather than a point-in-time assessment. Standards bodies – IETF for protocol specifications, 3GPP for telecom standards, OWASP CycloneDX for CBOM – define the technical frameworks within which migration operates. Organizations that participate in these ecosystem efforts shape the standards rather than being surprised by them.
What 120,000 tasks actually means for your organization
The 120,000-task figure comes from a specific program: a quantum-readiness migration plan for a large telecommunications operator with a complex technology estate spanning 5G radio networks, legacy 4G/3G systems, IP backbone, IT systems, OT infrastructure, and extensive IoT deployments. Your number will be different. A mid-size financial institution might face 30,000 to 50,000 tasks. A healthcare system with extensive medical device estates might reach 80,000. A large government department might exceed 100,000. A smaller enterprise with a simpler technology environment might face 5,000 to 15,000.
The specific number matters less than the recognition it forces: this is a program, not a project. It requires program management discipline, multi-year funding, cross-functional governance, and sustained executive commitment. It will not fit into a single budget cycle, a single team’s capacity, or a single vendor’s product roadmap.
The Enterprise PQC Migration Study’s finding that large enterprises face 12 to 15+ year baseline migration timelines collides uncomfortably with regulatory deadlines of 2030 to 2035. The arithmetic suggests that any organization that has not started is already behind schedule for the most aggressive deadlines (Australia’s 2030, India’s 2029 for CII), and that even the more generous 2035 timelines leave limited margin for the discovery, planning, and early implementation phases that must precede large-scale deployment.
The parallel with other large-scale technology transitions is instructive but should not create false confidence. SAP S/4HANA migrations – affecting a single business platform – routinely exceed timelines. PQC migration affects every system, not just one. If SAP migration complexity surprises experienced IT organizations, PQC migration complexity will overwhelm organizations that approach it with insufficient respect for the scope involved.
Conclusion: the case for honest planning
The 120,000-task program plan is not a scare tactic. It is an artifact of honest planning applied to genuine complexity. It emerges from the interaction of several factors that are each independently verifiable: cryptography is embedded in every layer of every enterprise system, PQC algorithms have fundamentally different characteristics that cascade through infrastructure, regulatory timelines are fixed and converging, vendor dependencies multiply the coordination burden, OT and IoT constraints create irreducible complexity, skills are scarce, and the program must execute over a decade while maintaining continuous operations.
The organizations that will navigate this transition successfully are those that face the scale honestly, start now, and build the programmatic infrastructure – governance, discovery capabilities, CBOM processes, vendor management frameworks, crypto-agile architecture – that converts an overwhelming scope into manageable, sequenced, measurable work.
The organizations that wait for a simpler answer will not find one. The algorithms are standardized. The regulatory timelines are set. The threat is advancing. The only variable still within organizational control is when they choose to begin – and how rigorously they plan.
Want to go deeper? I cover the practical realities of quantum risk and post-quantum migration planning in much more depth in my SANS course SEC529: Quantum Security Readiness for Executives. I’m also expanding this framework in my upcoming book QuantumResistance.com. If you need support turning strategy into an executable program – CBOM-driven discovery, governance, vendor alignment, testing, and migration wave planning – my consulting team at AppliedQuantum.com can help.
Quantum Upside & Quantum Risk - Handled
My company - Applied Quantum - helps governments, enterprises, and investors prepare for both the upside and the risk of quantum technologies. We deliver concise board and investor briefings; demystify quantum computing, sensing, and communications; craft national and corporate strategies to capture advantage; and turn plans into delivery. We help you mitigate the quantum risk by executing crypto‑inventory, crypto‑agility implementation, PQC migration, and broader defenses against the quantum threat. We run vendor due diligence, proof‑of‑value pilots, standards and policy alignment, workforce training, and procurement support, then oversee implementation across your organization. Contact me if you want help.
Related Content